.webp)




Introduction
Fraud detection without data science is no longer a compromise forced on teams with limited budgets. It's a deliberate architecture choice that works. Most compliance teams at banks, fintechs, and insurers don't have dedicated ML engineers building custom fraud models. They have analysts, operations leads, and compliance officers who need systems that produce accurate results from day one. AI fraud detection platforms have matured to the point where non-technical teams can deploy meaningful protection in days, not months. This guide breaks down how to build a fraud detection strategy using tools designed for compliance teams, how to cut false positive rates without touching a model, and what to look for when evaluating platforms like Sardine and Unit21.
- Why Most Fraud Teams Don't Have a Data Science Team (and That's Fine)
- What Is AI Fraud Detection, Explained Simply
- How to Set Up Automated Transaction Monitoring
- The Real Cost of Fraud Alert Fatigue
- How to Reduce False Positives in Transaction Monitoring
Onboard Customers in Seconds
Why Most Fraud Teams Don't Have a Data Science Team (and That's Fine)
Building fraud detection without data science expertise used to mean accepting inferior protection. That assumption no longer holds. The platforms available today ship with pre-trained models built on billions of transactions across industries. The model training that once took months of data science work now happens on the vendor's side, before you sign the contract.
The real challenge for mid-market institutions isn't the absence of a data science team. It's knowing which levers to configure and which results to measure. That's a compliance and operations skill set, not a technical one.
The Data Science Gap in Mid-Market Financial Institutions
Most financial institutions outside the largest tier don't employ a dedicated fraud data scientist. Industry surveys consistently find that over 65% of community banks and credit unions manage fraud operations with fewer than five full-time staff, nearly all with compliance or operations backgrounds.
Industry surveys consistently find that over 65% of community banks and credit unions manage fraud operations with fewer than five full-time staff, nearly all with compliance or operations backgrounds.
This isn't a failure. It's a resource reality. The question is whether your tools can match what larger institutions accomplish with larger teams. For payment fraud prevention and AML compliance, the answer is yes, provided you choose the right transaction monitoring software and invest time in configuration rather than code.
What You Can Accomplish Without Custom Models
Pre-trained models handle the heavy statistical work. Your team's job is to configure risk tiers for your customer population, tune thresholds to match your acceptable false positive rate, and ensure your escalation workflows connect to your SAR filing process. None of that requires a data science background. It requires knowledge of your customers, your products, and your regulatory obligations, which your compliance team already has.
The honest limitation worth acknowledging: pre-trained models calibrated on general transaction data will be less precise than a custom model trained specifically on your data. The tradeoff is three months of setup and a data science hire versus two weeks of configuration and an analyst. For most mid-market institutions, that math is straightforward.
What Is AI Fraud Detection, Explained Simply
AI fraud detection is the automated identification of potentially fraudulent activity using machine learning and behavioral analytics, without requiring manual review of every transaction. Rather than relying solely on static rules, AI systems learn behavioral patterns from historical data and flag transactions that deviate from expected behavior in statistically significant ways.
AI fraud detection explained at its most basic: a model builds a behavioral profile for each customer or account, then scores every new transaction against that profile. High-deviation transactions get flagged. Low-deviation transactions pass through. The score reflects a combination of signals, not a single threshold trigger.
How Does AI Detect Fraud?
How does AI detect fraud without a human reviewing each transaction? By operating across multiple behavioral dimensions simultaneously. A single unusual signal, like a large transaction, might reflect a real customer need. But a combination of signals, such as a large transaction from an unfamiliar device in a new geography at an unusual hour, produces a much stronger indicator.
The model weighs these signal combinations against patterns from confirmed fraud cases in its training data. Transactions with similar multi-dimensional profiles to historical fraud get high risk scores. Analysts only see transactions that exceed a meaningful composite threshold, not every transaction that trips a single rule.
Machine Learning Fraud Detection: The Core Mechanics
Machine learning fraud detection uses supervised models trained on labeled fraud and non-fraud examples, unsupervised models that detect anomalous clusters without labeled training examples, and graph-based models that identify networks of related accounts behaving in coordinated ways.
Graph analysis is particularly effective for synthetic identity fraud, where individual accounts appear clean but their connection patterns reveal coordinated fabrication. If 40 accounts share the same device fingerprint, phone number pattern, or behavioral timing, a graph model flags the network even though no individual account would trigger a standard rule.
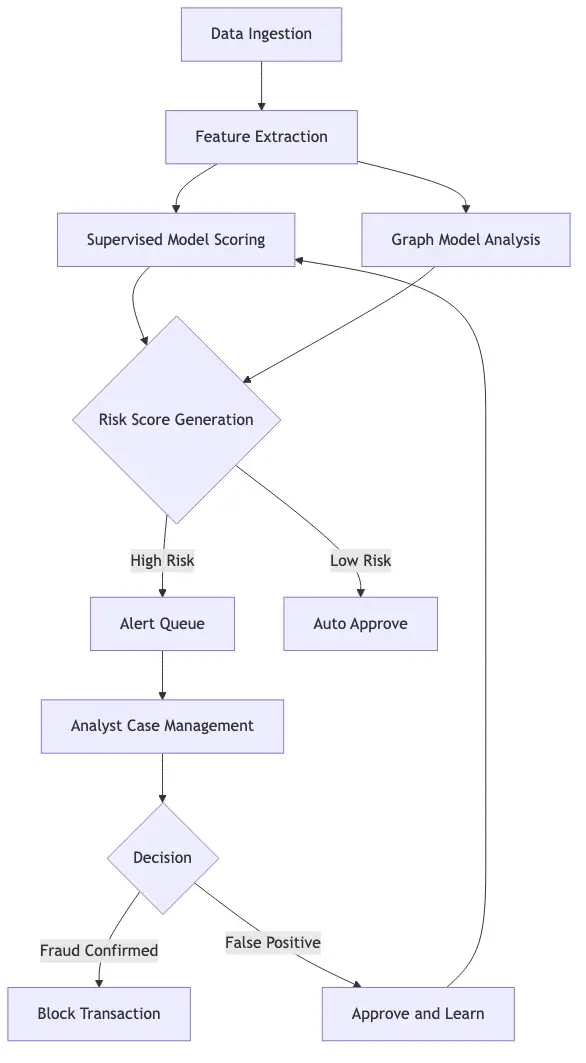
AI Fraud Detection in Banking vs. Fintech
AI fraud detection in banking operates under stricter explainability requirements than in most fintech contexts. Banks must document why a transaction was flagged and demonstrate that their models don't produce discriminatory outcomes. This pushes banks toward explainable AI tools where the system surfaces the top contributing risk factors for every alert.
Fintechs face faster fraud velocity but fewer explainability mandates. The NIST AI Risk Management Framework provides guidance on explainability standards that regulated institutions are increasingly referencing as regulatory scrutiny of AI models grows.
How to Set Up Automated Transaction Monitoring
Automated transaction monitoring is the operational core of fraud detection without data science. You configure the system with your risk rules and thresholds. It runs continuously against your transaction stream. Analysts only review cases that cross a meaningful threshold, not every transaction moving through your platform.
Most modern platforms complete technical integration in one to three weeks via API. The configuration phase, where you define your risk rules, customer tiers, and alert thresholds, typically takes two to four weeks and is handled entirely by your compliance team. The honest answer about setup difficulty: the integration is rarely the bottleneck. Getting the rules calibrated to your specific transaction mix takes iteration, and that iteration is ongoing.
What Transaction Monitoring Software Actually Does
Transaction monitoring software processes every payment, transfer, and account action against a combination of rule-based triggers and model-based risk scores. When a transaction exceeds a threshold, it creates a case in your analyst queue. Analysts review context, investigate, and either close the case or escalate.
Good transaction monitoring software also automates regulatory reporting. When a case warrants a Suspicious Activity Report, the platform pre-fills the report with transaction details, account history, and alert context. For teams filing 20-50 SARs per month, that saves 30-60 minutes per filing.
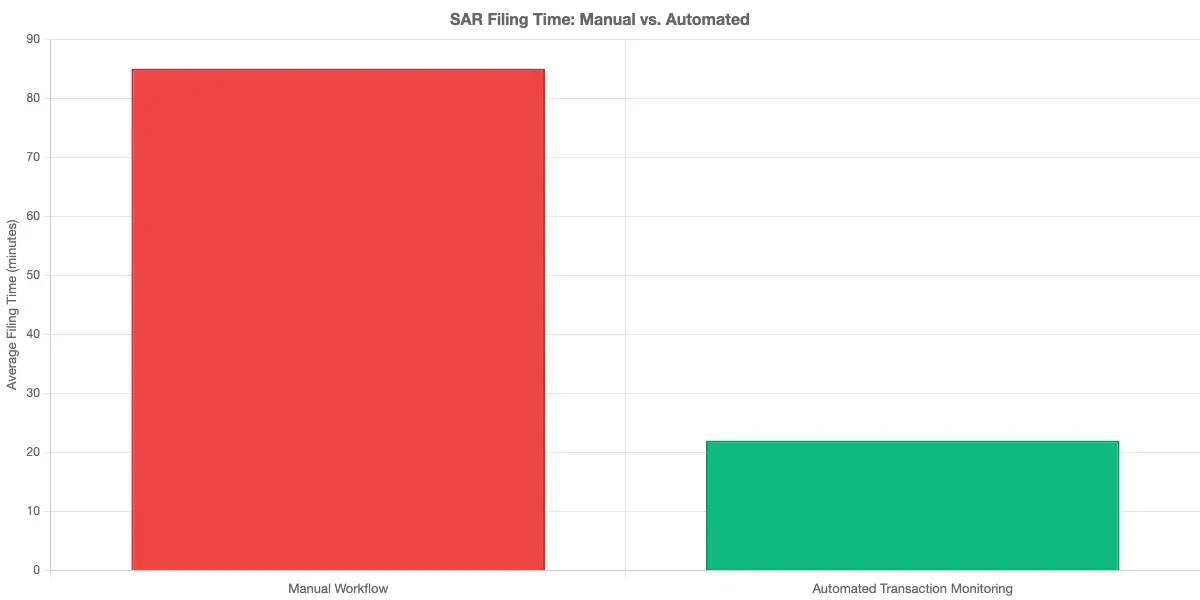
Transaction Monitoring Cost: What to Budget
Transaction monitoring cost depends on transaction volume and the scope of features deployed. SaaS platforms typically price by transactions reviewed, active customers monitored, or alerts generated. For a mid-size institution processing 500,000 transactions per month, expect to budget $8,000-$30,000 per month for a full-featured platform.
The more useful calculation is total cost compared to current fraud losses plus analyst time spent on false positives. Most institutions find payback within 12 months when they account for both fraud prevented and analyst hours reclaimed from false positive review.
The Real Cost of Fraud Alert Fatigue
Fraud alert fatigue is the operational consequence of too many low-quality alerts reaching analyst queues. It's not primarily a morale problem, though it becomes one over time. It's a precision problem that degrades the entire fraud detection function from the inside.
When 90% of alerts are false positives, analysts begin treating the alert queue as noise. Real fraud hides in that queue and receives the same shallow investigation as the false positives surrounding it. Escape rates increase, chargeback losses accumulate, and regulatory audit risk grows because examiners look at investigation quality, not just alert volume.
Why Alert Fatigue Kills Compliance Programs
As covered in How Agentic AI Fraud Agents Cut False Positives by 80%, analyst attention is a finite resource. Each false positive burns a share of it. The true cost of a false positive isn't just the analyst time spent on that alert. It's the degraded quality of every real-fraud investigation that follows in the same workday.
As covered in How Agentic AI Fraud Agents Cut False Positives by 80%, analyst attention is a finite resource.
Compliance programs where analysts review 400-500 alerts per day are statistically likely to miss real fraud. Regulators examining these programs during audits flag shallow investigation depth as a material weakness, regardless of the alert volume metrics the institution reports.
False Positive Cost in Fraud: The Hidden Budget Drain
The false positive cost in fraud is almost always underestimated in budget planning. Manual review costs $15-$50 per alert across the full investigation workflow, depending on case complexity and analyst seniority. At a 90% false positive rate for a team managing 8,000 alerts monthly, you're spending $108,000-$360,000 per month on alerts that produce no actionable case.
Cutting the false positive rate from 90% to 65% at the same alert volume doesn't just reduce direct costs. It triples the investigation bandwidth available for real fraud and immediately improves your regulatory audit posture.
How to Reduce False Positives in Transaction Monitoring
The most common question compliance teams ask about their fraud detection without data science setup is some version of: how do we get fewer bad alerts? False positives fraud detection is the term used when legitimate transactions trigger alerts, wasting analyst time and creating investigation backlogs that obscure real fraud.
Most false positives in rule-based systems come from rules that were calibrated for a specific transaction profile at deployment and never updated as customer behavior evolved. Rules that made sense for your 2021 transaction mix may be wildly miscalibrated for your 2025 volumes.
False Positive Rate in Fraud Detection: What's Acceptable?
The false positive rate in fraud detection has no universal target, but industry practice flags any rate above 90% as a signal that your ruleset needs audit. In AML transaction monitoring specifically, 80-90% false positive rates are common in legacy rule-heavy systems. AI-assisted systems typically achieve 40-65% false positive rates on the same transaction data, without adding staff.
The false positive rate in fraud detection has no universal target, but industry practice flags any rate above 90% as a signal that your ruleset needs audit.
To make those numbers concrete: moving from 90% to 60% false positives means your analysts are spending three times as much time on real investigations as before, without any change in headcount.
Reduce False Positives in Transaction Monitoring: Three Proven Approaches
To reduce false positives in transaction monitoring, start with these three approaches:
Threshold tuning: Identify the 20% of rules generating 80% of alerts. Review their recent false positive rates and raise thresholds on high-volume, low-yield rules first. Schedule this review quarterly.
Behavioral context layering: Add customer history to each rule trigger. A $5,000 wire transfer should only alert if it's large relative to that customer's transaction history, not relative to an absolute dollar threshold applied uniformly.
AI risk score pre-filtering: Configure your system to only send alerts to analyst queues when both a rule triggers AND the customer's composite risk score exceeds a threshold. This filter alone reduces alert queue volume by 30-50% in most deployments.
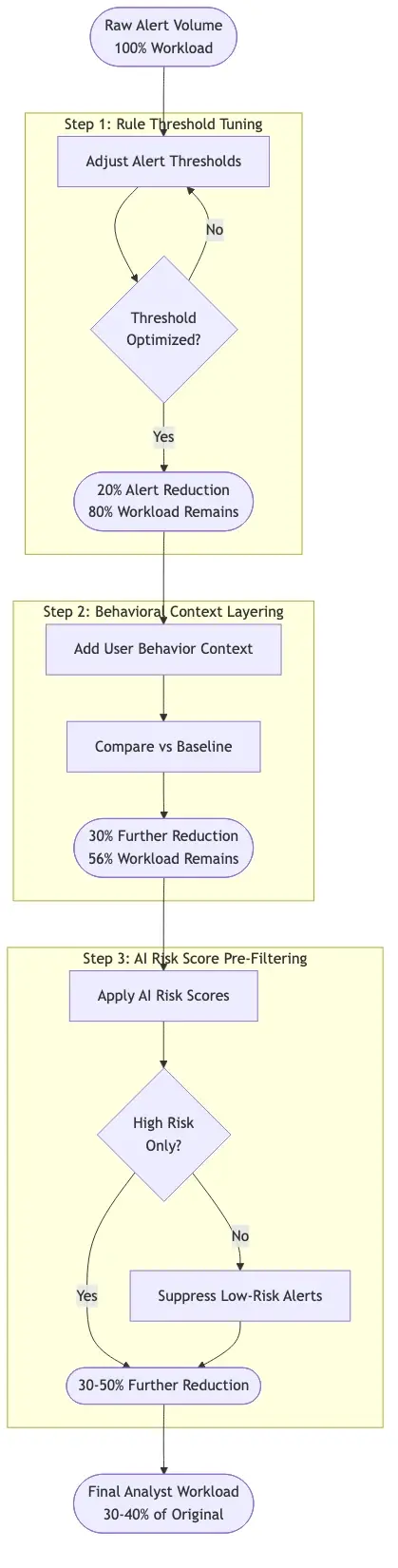
How to Reduce False Positives in AML Specifically
How to reduce false positives in AML requires a different lens than general payment fraud. Most AML false positives come from geographic triggers on countries in monitoring lists for reasons unrelated to the specific customer's risk profile, and name-match false hits in sanctions screening.
The most effective fix is risk-based composite scoring: require multiple risk factors to align before generating an alert, rather than treating any single trigger as sufficient. Reducing False Positives: Rule-Based Systems vs. AI-Driven Solutions details this framework with specific implementation steps for AML programs.
Real-Time Fraud Detection for Banks and Fintechs
Real time fraud detection means scoring a transaction at the moment it occurs and acting on that score before the transaction settles, not hours later in batch review. For card authorizations, the decision window is under 100 milliseconds. For ACH and wire transfers, it's seconds.
The difference is loss prevention architecture. A fraud decision at authorization time stops the transaction. A fraud decision made 24 hours later creates a chargeback, a customer service case, and a write-off. Both detect fraud. Only one prevents the loss.
Real-Time Fraud Detection Banks Use Today
Real time fraud detection banks deploy through two primary architectures. In-line scoring runs the fraud model as part of the authorization flow, blocking or tagging the transaction before it completes. Parallel scoring runs the model simultaneously with authorization, generating post-authorization alerts for analyst review.
In-line scoring prevents fraud before it happens but introduces false-decline risk: legitimate transactions blocked based on model score. False declines carry their own cost in customer attrition and dispute handling. Calibrating the threshold between fraud blocking and false declines is the primary ongoing tuning challenge for in-line real-time systems.
For card environments, the functional latency limit for in-line scoring is 50ms. Most modern cloud-based AI fraud detection software meets this at baseline. What varies is model accuracy at that latency. Ask vendors for their false positive rates at sub-50ms scoring specifically, not their offline evaluation benchmarks, which often diverge significantly from live production performance.

Synthetic Identity Fraud: The Threat Rules Won't Catch
Synthetic identity fraud is the fastest-growing fraud category in US financial services. FinCEN advisories identify synthetic identity fraud as a systemic threat, with fabricated personas built from a combination of real and invented personal data, often using a valid Social Security number obtained from a child or recently deceased individual combined with invented contact and address details.
Rule-based systems struggle because individual synthetic accounts pass standard verification. They have consistent addresses, meet KYC requirements, and build credit histories deliberately over months before committing fraud. The fraud is in the network, not the individual account.
How AI Fraud Detection Software Spots Synthetic Identities
AI fraud detection software catches synthetic identity networks through graph analysis of account relationships. While individual accounts look legitimate, synthetic identity fraud operations share device fingerprints, phone numbers, behavioral timing patterns, and counterparty relationships across dozens of fabricated accounts in ways that genuine customers don't.
Detecting Synthetic Identity Fraud in Real-Time details the specific detection approach. The core mechanism: graph-based ML models identify rings of synthetic accounts that share structural fingerprints invisible to any static rule but statistically anomalous to a model trained on network behavior.
Choosing AI Fraud Detection Software: Sardine vs Unit21
The sardine vs unit21 comparison comes up in nearly every mid-market compliance team's vendor evaluation. Both platforms are designed for non-technical teams. Both offer real-time scoring, case management, and AML transaction monitoring without requiring data science or engineering resources. The right choice depends on your primary fraud problem.
| Feature | Sardine | Unit21 |
|---|---|---|
| Primary strength | Payment fraud + identity signals | AML case management |
| No-code rules engine | Strong | Strong |
| Real-time API scoring | Yes | Yes |
| Graph analytics | Limited | Available |
| SAR automation | Basic | Full |
| Regulatory audit trail | Moderate | Strong |
| Typical customer | Fintechs, neobanks | Banks, crypto platforms |
Sardine deploys faster and performs better in high-velocity payment fraud environments. Unit21 is more mature for institutions with heavy AML workflows and SAR filing obligations. The decision comes down to whether your primary exposure is payment fraud prevention or AML compliance reporting.
What to Look For in AI Fraud Detection Software
When evaluating AI fraud detection software for a team building fraud detection without data science resources, prioritize these criteria:
- Pre-trained models for your transaction type: You should see meaningful risk scores in production within days of going live, not after months of model training.
- Explainable scoring outputs: Analysts need to understand why a transaction was flagged. This also satisfies regulatory documentation requirements when your models face audit.
- Time-to-production data: Ask vendors for median deployment timelines for customers with your transaction profile, not best-case examples from their fastest deployments.
- False positive benchmarks at your volume: Request performance data from customers with similar transaction mixes, not platform-wide averages.
For a deeper evaluation framework, AI vs. Traditional Fraud Detection: Key Differences Every Risk Officer Should Know covers the tradeoffs between AI-native platforms and rule-based legacy systems.
- Building fraud detection without data science expertise used to mean accepting inferior protection.
- AI fraud detection is the automated identification of potentially fraudulent activity using machine learning and behavioral analytics, without requiring manual review of every transaction.
- Automated transaction monitoring is the operational core of fraud detection without data science.
- Fraud alert fatigue is the operational consequence of too many low-quality alerts reaching analyst queues.
- The most common question compliance teams ask about their fraud detection without data science setup is some version of: how do we get fewer bad alerts?
Onboard Customers in Seconds
Conclusion
Fraud detection without data science is achievable for any compliance team that selects tools designed for operational use and invests in configuration rather than code. Automated transaction monitoring, real time fraud detection scoring, and AI-driven false positive reduction are mature capabilities available to institutions of every size, not just the largest banks.
The teams that struggle aren't the ones without data scientists. They're the ones running on rule sets from years past, with no systematic process for measuring false positive cost in fraud or improving AI fraud detection accuracy over time. Better tools don't fix a stale operational process automatically. They give you better signals to act on.
Start by measuring your current false positive rate. Calculate your transaction monitoring cost per alert closed. Then iterate from there. For strategic framing on how AI fits your broader fraud program, Card Fraud Analytics: AI-Powered Fraud Detection Strategy for Risk Heads is a strong next read.



Share this article