.webp)




Introduction
Machine learning fraud detection has become the single most effective defense financial institutions have against fraudsters who adapt faster than any rule set can keep up with. Ten years ago, a bank's fraud team might block a transaction because it triggered three static rules: wrong geography, odd hour, unusual amount. Fraudsters learned those rules. Today they probe systems to find the gaps, and most legacy detection setups give them plenty to work with. This guide breaks down how ML-based fraud detection actually works, what specific threats it addresses, and what to look for when evaluating platforms for your organization.
- Why Traditional Fraud Systems Are Breaking Down
- How Machine Learning Fraud Detection Actually Works
- The Key ML Techniques Behind Fraud Detection
- Synthetic Identity Fraud and How ML Catches It
- Biometric Identity Verification and Liveness Detection
Onboard Customers in Seconds
Why Traditional Fraud Systems Are Breaking Down
Rule-based fraud systems were built for a world that no longer exists. A typical legacy setup works like this: analysts observe past fraud patterns, write IF/THEN rules, and flag transactions that match. It sounds logical. In practice, it fails in three ways.
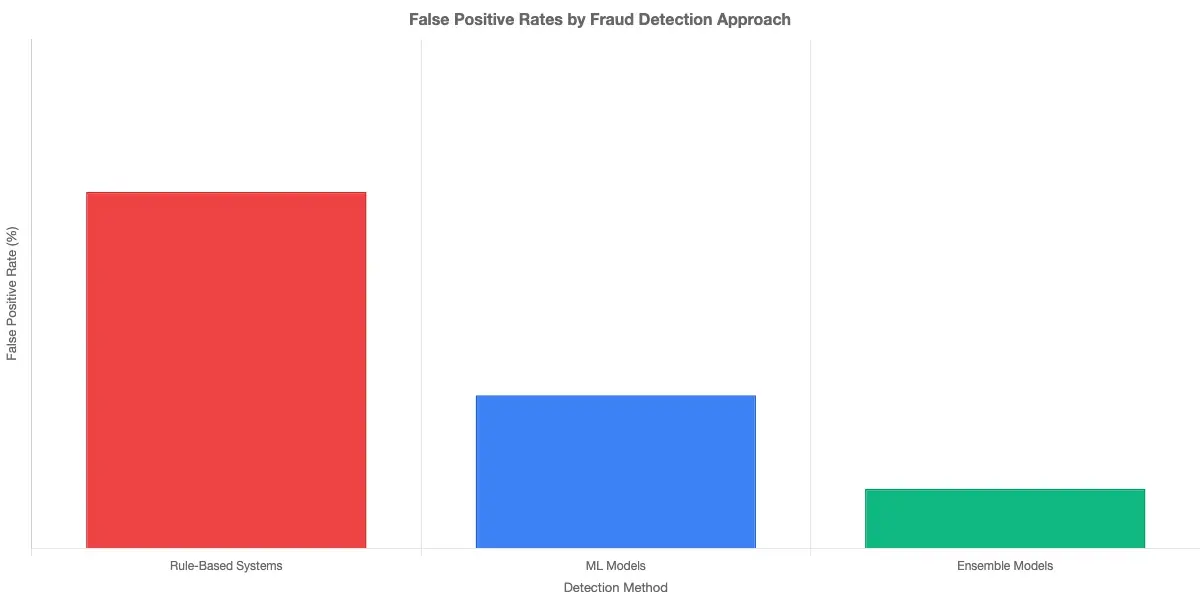
First, rules are static. Fraudsters reverse-engineer them within weeks. Second, rules generate enormous false positive rates, which means legitimate customers get blocked constantly. According to Wikipedia's overview of fraud detection, false declines frustrate real customers and generate significant operational costs alongside lost revenue. Third, rules can't handle the combinatorial complexity of modern payment rails, where a single customer might touch eight systems before a payment settles.
This is the core argument for ML: it finds patterns humans can't specify in advance. For a deeper comparison between rule-based approaches and AI-driven solutions, the analysis in AI vs. Traditional Fraud Detection: Key Differences Every Risk Officer Should Know walks through the operational tradeoffs in detail, including cost per false positive and analyst workload comparisons.
How Machine Learning Fraud Detection Actually Works
Machine learning fraud detection uses statistical models trained on historical transaction data to score new events in real time. The basic process runs like this:
- Collect labeled data: transactions marked as fraud or legitimate by analysts
- Train a model to identify the features that best separate the two classes
- Deploy the model to score incoming transactions, typically in under 50 milliseconds
- Feed new confirmed outcomes back into the training set to continuously improve accuracy
The key difference from rules is that the model weights hundreds of variables simultaneously. A rule says "flag transactions over $10,000 from a new device." An ML model says "this transaction has a 94% probability of fraud based on 340 features, including device fingerprint, typing cadence, session duration, transaction velocity, geolocation mismatch, and merchant category risk."
A rule says "flag transactions over $10,000 from a new device." An ML model says "this transaction has a 94% probability of fraud based on 340 features, including device fingerprint, typing cadence, session duration, transaction velocity, geolocation mismatch, and merchant category risk."
The probability score is what matters operationally. Teams set thresholds: above 90%, block automatically; between 60-90%, route to a human reviewer; below 60%, approve. These thresholds are adjustable, which is something rule systems can't offer. A well-calibrated ML system also lets you set different thresholds for different customer segments, which is where identity verification fintech platforms add particular value during high-risk onboarding events.
The Key ML Techniques Behind Fraud Detection
Not all machine learning fraud detection systems use the same approach. Here are the four techniques that appear most often in production financial systems:
Supervised learning: Trained on labeled fraud and non-fraud datasets. Fast and accurate when you have good training data. The challenge is class imbalance: fraud events typically represent less than 0.1% of all transactions, so models need careful calibration to avoid defaulting to "approve everything."
The challenge is class imbalance: fraud events typically represent less than 0.1% of all transactions, so models need careful calibration to avoid defaulting to "approve everything."
Unsupervised learning (anomaly detection): No labels required. The model learns what "normal" looks like for each customer or account, then flags deviations. This catches novel fraud patterns that supervised models miss because they've never seen them before.
Graph neural networks: These map relationships between accounts, devices, merchants, and IP addresses. A fraudster using the same device across 12 accounts creates a graph pattern that transaction-level models miss entirely. Graph analysis surfaces it immediately.
Ensemble models: Combine multiple models and aggregate their scores. This is the current production standard because no single algorithm dominates across all fraud types. Most mature platforms run 5-10 models in parallel and blend their outputs.
Synthetic Identity Fraud and How ML Catches It
Synthetic identity fraud is one of the fastest-growing financial crimes globally. Unlike stolen identity fraud, where a real person is victimized immediately, synthetic identity fraud uses fabricated identities to build seemingly legitimate credit histories before fraudsters cash out. The Financial Action Task Force (FATF) identifies synthetic identities as a key vehicle for money laundering, particularly in digital banking channels where in-person verification doesn't occur.
What Makes Synthetic Identities Hard to Spot
A synthetic identity typically combines a real Social Security number (often from a child or deceased person) with a fabricated name and address. The fraudster spends 12-24 months building credit history, making small purchases and paying them off. To traditional onboarding systems, this looks like a responsible new customer with a thin credit file. Nothing in a standard rule set triggers an alert.
ML's Approach to Synthetic Identity Detection
Synthetic identity fraud detection using machine learning looks at behavioral consistency over time. Red flags include:
- Identity element combinations that don't appear in any historical cross-reference datasets
- Credit-building patterns that statistically match known synthetic fraud profiles
- No organic digital footprint associated with the identity across public data sources
- Sudden bust-out behavior after a dormant period: maxing credit lines and disappearing
Our post on detecting synthetic identity fraud in real time covers the technical mechanics in depth, including how graph-based models specifically expose synthetic identity rings operating across multiple institutions simultaneously.
Biometric Identity Verification and Liveness Detection
Biometric identity verification adds a layer that synthetic fraud and stolen credentials can't easily defeat: proof that the human presenting the identity actually exists and matches the document. This matters most during KYC onboarding, where kyc onboarding speed has to be balanced carefully against fraud risk, and during account recovery or high-value transaction authorization.
Liveness detection fraud is now a specific attack category. Fraudsters submit photos of photos, video replays, or 3D-printed masks to spoof face-matching systems. Modern liveness detection models check for micro-expressions, depth cues, texture inconsistencies, and reflection patterns that indicate a live human rather than a spoofed presentation. Passive liveness detection, where the user does nothing special and the model still detects spoofs, is production-ready at several vendors.
Digital identity proofing combines document verification (confirming an ID document is genuine and unaltered) with biometric matching (verifying the document holder is present). ML models trained on millions of ID documents can detect forgeries, laminate separation, and digital editing artifacts that human reviewers miss. The NIST Digital Identity Guidelines provide a useful framework for evaluating assurance levels across different proofing methods.
For organizations handling high volumes of KYC onboarding, the speed tradeoff is real. Biometric verification adds 30-90 seconds to the onboarding flow. Organizations that skip it face average synthetic identity losses of $10,000-$15,000 per account before detection, which makes the 60-second friction seem reasonable by comparison.
Machine Learning Fraud Detection in Practice
This is where the gap between vendor demos and production reality tends to show up. A few honest points about deploying machine learning fraud detection at scale:
Cold start is a real problem. New ML systems need 60-90 days of transaction data to calibrate properly. Organizations migrating from legacy systems should plan for elevated false positives in the first quarter after deployment.
Feature engineering still matters. The raw data a model receives determines what it can learn. Poor data pipelines produce poor models regardless of algorithm sophistication. The most common production failure point is stale or misaligned feature data, not model quality.
Explainability is a regulatory requirement. If a model declines a credit application or freezes an account, most jurisdictions require an explainable reason. "The model said so" is not sufficient. Modern ML platforms include SHAP values or similar attribution tools to generate human-readable explanations for individual decisions.
The operational guide on AI-powered fraud detection strategy for risk heads goes deeper on structuring operational workflows around ML outputs, including escalation paths and exception handling procedures that keep fraud teams effective without burning them out on low-value reviews.
One persistent challenge worth naming: ML models can reduce false positives by 40-60% compared to rule systems, but they don't eliminate them. The goal is to shift analyst time from high-volume low-risk reviews to low-volume high-risk investigations, not to remove humans from the loop entirely.
One persistent challenge worth naming: ML models can reduce false positives by 40-60% compared to rule systems, but they don't eliminate them.
Deepfake Detection in Banking
Deepfake detection banking is an emerging but urgent problem. Audio and video deepfakes are already being used to impersonate executives in business email compromise schemes and to bypass voice authentication systems. Widely reported incidents describe finance workers defrauded of tens of millions of dollars after attackers used video deepfakes to impersonate company leadership during video calls, a threat that has escalated sharply since 2023.
Machine learning models for deepfake detection look for:
- Unnatural blending artifacts at face boundaries
- Inconsistent lighting and shadow physics
- Micro-temporal inconsistencies between audio and lip movement
- Statistical patterns in pixel-level noise that differ from real camera sensor noise
The honest assessment: deepfake detection is a genuine arms race. Generation models and detection models improve together, and no detection system is 100% reliable right now. The stronger defense is layered: require out-of-band confirmation for high-value transactions, use behavioral analytics alongside biometric checks, and train staff to be skeptical of urgent requests made exclusively through video channels.
Zero Trust and Machine Learning: Better Together
Zero trust financial services architecture operates on the assumption that no user, device, or network segment is inherently trusted, even inside the perimeter. Every access request is verified continuously. Machine learning fraud detection fits naturally into a zero trust security framework because ML provides continuous behavioral signals that feed directly into access decisions in real time.
A practical example: a user authenticates normally at 9 AM. By 11 AM, their transaction pattern has shifted significantly: higher amounts, different merchant categories, new beneficiary accounts added. A zero trust system paired with machine learning fraud detection can step up authentication mid-session without logging the user out, requiring re-verification via biometric or OTP before the unusual transactions proceed.
For organizations building this architecture in banking environments, our post on zero trust security architecture for banking operations covers the access control layer in detail. The ML fraud detection component is one piece of a broader architecture that also requires continuous session scoring, privileged access management, and micro-segmentation of internal payment systems.
The integration point is the identity verification API. Most modern ML fraud platforms expose a risk score via API that feeds directly into access control policies. A score above 80 triggers additional authentication. A score above 95 triggers account lock and human review. This makes machine learning fraud detection a native part of access policy rather than a bolt-on check.
How to Evaluate a Machine Learning Fraud Detection Platform
When comparing platforms, the marketing language is nearly identical across vendors. Here are the specific questions that separate real capability from demo performance:
- What is the model's precision and recall on your transaction type? Ask for evidence on data similar to your portfolio, not generic industry benchmarks.
- How does the platform handle cold start for new customers? New-to-bank customers have no behavioral baseline. What happens in their first 30 days?
- What is latency at the 99th percentile? An average of 20ms means nothing if the 99th percentile is 800ms during peak load.
- How are explainability outputs structured? Can they feed your customer communication system for regulatory adverse action notices?
- What does the retraining cycle look like? Weekly retraining catches model drift faster than monthly; real-time retraining usually introduces instability.
- What is the false positive rate segmented by customer tier? A 0.5% false positive rate sounds low until it translates to 50,000 blocked legitimate transactions per day for a mid-size bank.
Organizations that get the most value from machine learning fraud detection treat the platform as infrastructure, not software. They invest in data quality, operational processes around model outputs, and continuous feedback loops between fraud analysts and data science teams. For organizations also managing API security across their fraud detection stack, the guidance in API security strategies for CISOs in banking is directly applicable, particularly around rate limiting and authentication for ML scoring endpoints.
- Rule-based fraud systems were built for a world that no longer exists.
- Machine learning fraud detection uses statistical models trained on historical transaction data to score new events in real time.
- Not all machine learning fraud detection systems use the same approach.
- Synthetic identity fraud is one of the fastest-growing financial crimes globally.
- Biometric identity verification adds a layer that synthetic fraud and stolen credentials can't easily defeat: proof that the human presenting the identity actually exists and matches the document.
Onboard Customers in Seconds
Conclusion
Machine learning fraud detection is not a magic switch. It's a capability that requires clean data, clear thresholds, explainable outputs, and operational processes built around its results. What it delivers, when implemented properly, is a detection layer that adapts continuously, scores transactions in milliseconds, and handles the complexity of modern financial systems at a scale that static rules cannot match. The threats it addresses, from synthetic identity fraud to deepfake-based social engineering and real-time behavioral anomalies, are real and increasing. For CISOs, compliance officers, and risk heads evaluating their fraud stack, the question is no longer whether to adopt ML-based detection. It's which capabilities to prioritize first and how to integrate them into the broader security architecture your institution is already building. Start with data quality fundamentals, choose a platform that provides explainable scores, and treat ML outputs as decision support rather than fully autonomous decisions.



Share this article