.webp)




Introduction
The false positive cost in fraud detection doesn't appear on a single line in your budget, but it quietly erodes your operations, your customer relationships, and your analyst team's capacity every day. Most fraud teams track one number: how much fraud did we stop? The harder question, the one most organizations avoid, is how many legitimate transactions did we also stop?
The answer is usually uncomfortable. For every confirmed fraud case, financial institutions typically flag between 10 and 50 legitimate transactions as suspicious. Your compliance team spends the majority of its time reviewing transactions that are completely fine, while actual fraudsters find the gaps. This post breaks down the real economics of false positives, why AI fraud detection changes the math, and what teams in banking, insurance, and high-risk supply chains can do about it.
- The Real Cost of False Positives in Fraud Detection
- Fraud Alert Fatigue: The Human Cost Nobody Talks About
- What AI Fraud Detection Actually Does Differently
- Real-Time Fraud Detection: Speed Is Not the Only Metric
- Automated Transaction Monitoring: What the Software Market Gets Right and Wrong
Onboard Customers in Seconds
The Real Cost of False Positives in Fraud Detection
False positives in fraud detection occur when a legitimate transaction or customer is flagged as potentially fraudulent. Each one carries a chain of costs that most organizations only partially account for.
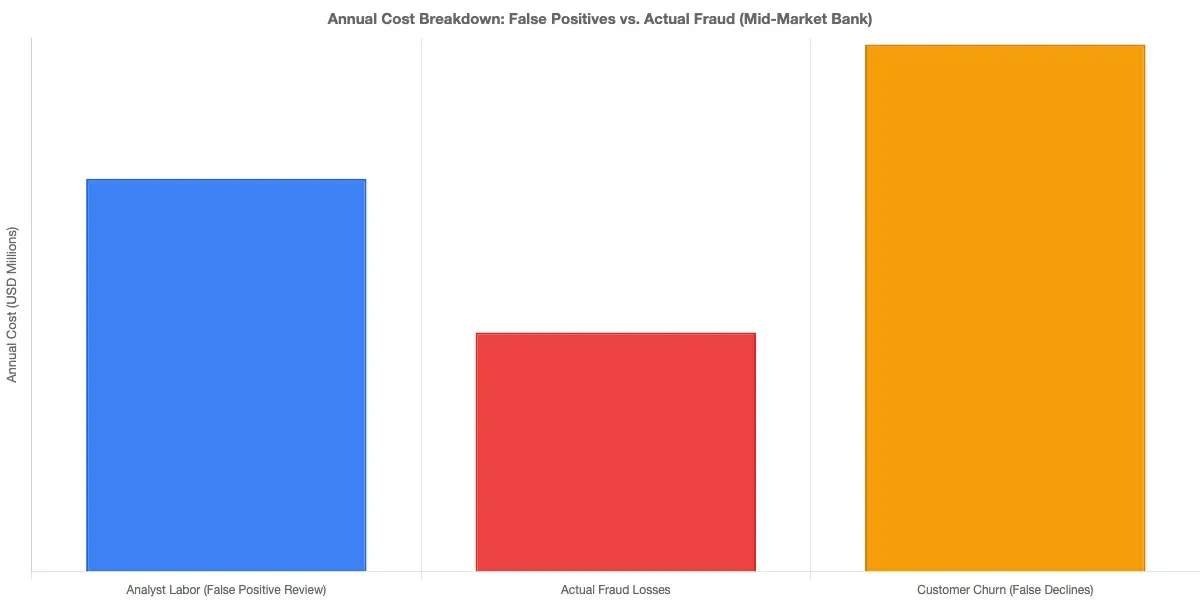
The direct costs are the easiest to measure. Manual review teams at mid-market banks average 7-10 minutes per alert. At a false positive rate of 95% (meaning 95 out of 100 alerts are legitimate), a team handling 1,000 alerts per day spends the equivalent of roughly 110 analyst-hours per day reviewing non-fraud. At typical compliance analyst salaries of $65,000-$85,000 annually, the waste compounds to millions in misdirected labor per year.
At a false positive rate of 95% (meaning 95 out of 100 alerts are legitimate), a team handling 1,000 alerts per day spends the equivalent of roughly 110 analyst-hours per day reviewing non-fraud.
The indirect costs are where it gets more damaging:
- Customer friction: A flagged transaction means a declined payment, a frozen account, or a hold lasting 24-72 hours. Research from Javelin Strategy & Research has found that a significant share of cardholders who experience a false decline consider switching financial providers within 90 days.
- Revenue leakage: Payment fraud prevention calibrated too aggressively blocks legitimate high-value purchases. For a bank processing $50 million in daily transactions, even a 0.5% false block rate means $250,000 in daily transaction value turned away.
- Regulatory exposure: Systems that freeze accounts without adequate justification can attract scrutiny under fair lending and anti-discrimination frameworks, creating a new compliance problem on top of the original one.
Fraud Alert Fatigue: The Human Cost Nobody Talks About
Fraud alert fatigue happens when analysts review so many false positives that they begin clearing alerts without adequate scrutiny. The paradox: your system generates too many alerts, analysts stop taking them seriously, and real fraud slips through anyway.
The Financial Crimes Enforcement Network (FinCEN) has identified alert fatigue as one of the primary reasons Suspicious Activity Reports (SARs) are filed inconsistently across institutions. An analyst who has cleared 200 false positives in a row on a Tuesday afternoon is not in the right state to catch a sophisticated synthetic identity fraud scheme.
The compounding effect matters:
- High false positive volumes create analyst alert fatigue
- Alert fatigue leads to missed genuine fraud
- Missed genuine fraud produces actual losses
- Actual losses create pressure to tighten detection rules
- Tighter rules generate even more false positives
This cycle is how transaction monitoring costs spiral out of control. Compliance teams operating under this dynamic often find that their transaction monitoring software was configured so conservatively that analysts are clearing 200-plus alerts per shift, with genuine fraud making up less than 2% of total alerts.
Compliance teams operating under this dynamic often find that their transaction monitoring software was configured so conservatively that analysts are clearing 200-plus alerts per shift, with genuine fraud making up less than 2% of total alerts.
What AI Fraud Detection Actually Does Differently
AI fraud detection uses machine learning models trained on historical transaction patterns to score each transaction's fraud probability in real time, rather than checking it against a fixed list of alert conditions.
Rule-based transaction monitoring asks: "Does this transaction match any of our alert conditions?" If yes, flag it. The problem is that conditions accurate two years ago now produce hundreds of false flags because legitimate user behavior has shifted.
Machine learning fraud detection asks a different question: "Given everything we know about this customer, this merchant, this location, this device, and this time of day, what is the probability that this specific transaction is fraudulent?" The output is a risk score, not a binary decision.
This approach does several things rule-based systems structurally cannot:
- Behavioral baselining: ML models learn what "normal" looks like for each individual customer, so a $4,000 wire transfer from a customer who regularly makes $4,000 wire transfers doesn't trigger an alert.
- Contextual scoring: A transaction from a new device in a new country gets a different risk score for a customer who just booked international travel versus one who hasn't moved in years.
- Network-level pattern detection: Coordinated fraud across multiple accounts often looks innocent at the individual account level but suspicious when analyzed as a group.
For a structural comparison that risk officers evaluating a platform transition will find useful, our post on AI vs. Traditional Fraud Detection covers the operational and architectural differences in detail.
Real-Time Fraud Detection: Speed Is Not the Only Metric
Real-time fraud detection in banking is table stakes now. The question is no longer whether your system makes a decision in milliseconds; it's whether that millisecond decision is the right one.
A system that rejects a transaction in 200ms based on a single velocity rule is fast. If it's wrong 95% of the time, speed is working against you. You're delivering a bad customer experience faster.
If it's wrong 95% of the time, speed is working against you.
Effective real-time fraud detection combines four things:
- Sub-second transaction scoring using pre-trained ML models that don't require expensive database lookups at decision time
- Streaming enrichment that pulls device fingerprints, geolocation, and behavioral signals in real time alongside the transaction itself
- Dynamic thresholding that adjusts risk tolerance based on transaction context: a $15 coffee purchase and a $15,000 wire transfer require different risk frameworks
- Continuous feedback loops that update model scores as new confirmed fraud and confirmed legitimate transactions come in, often within hours rather than weeks
Research compiled by organizations including the Bank for International Settlements (BIS) in its fintech and financial stability working papers indicates that institutions using adaptive ML-based fraud systems consistently report lower false positive rates than those using static rule engines, while maintaining or improving fraud catch rates. The savings in analyst time and customer friction are where the ROI case for AI fraud detection in banking becomes concrete.
Automated Transaction Monitoring: What the Software Market Gets Right and Wrong
Automated transaction monitoring software has matured considerably. Products like Sardine, Unit21, Featurespace, and Actimize all offer ML-enhanced capabilities that promise to reduce false positive cost in fraud detection. There is, however, meaningful variation in how they actually deliver.
Sardine vs Unit21 is a comparison that comes up regularly for mid-market fintechs. Sardine focuses heavily on device intelligence and behavioral biometrics at the point of account creation and transaction, making it particularly strong for stopping first-party fraud and synthetic identity fraud before it reaches the monitoring layer. Unit21 takes a more modular approach, with flexible rule management, case management, and reporting workflows that compliance teams find easier to customize to their own processes.
Neither tool eliminates the calibration requirement. Both ship with default rule sets that, in most environments, produce unacceptably high false positive rates until tuned to your specific customer base and transaction mix. Teams that implement these platforms expecting out-of-the-box accuracy are consistently disappointed.
Key criteria for evaluating automated transaction monitoring platforms:
| Criterion | What to Look For |
|---|---|
| False positive rate | Benchmark against your own transaction data, not vendor-provided figures |
| Model explainability | Can analysts understand why a specific transaction was flagged? |
| Feedback loop speed | How quickly do confirmed fraud and non-fraud decisions update model scores? |
| Signal integration | Does it incorporate behavioral, device, and network signals or only transaction data? |
| Case management | Can analysts resolve cases efficiently without switching between multiple tools? |
For teams deciding between rule-based and ML-driven approaches, our comparison of rule-based systems vs. AI for reducing false positives lays out the trade-offs with specifics on calibration effort and time-to-value.
Synthetic Identity Fraud: The Case That Breaks Standard Models
Synthetic identity fraud deserves its own section because it exposes a specific weakness in how most transaction monitoring software is calibrated.
Synthetic identity fraud occurs when criminals combine real and fabricated personal information to create a new identity, then build a seemingly legitimate account history over months or years before committing fraud.
The challenge for false positive management here is inverted. These accounts look extremely legitimate for a long time. They pass KYC checks because the identity components are real. They build a transaction history. They make small, normal-looking payments for six to twelve months. When the fraud finally occurs, it is often a sudden, large bust-out event.
Systems calibrated to minimize false positives often whitelist these accounts because their historical behavior looks clean. The fraud, when it comes, looks like an anomaly from a trusted account rather than a fraud pattern that was building for months.
Detecting synthetic identity fraud in real time requires looking beyond the individual account. Our guide to detecting synthetic identity fraud covers the operational detail: specifically, analyzing whether the same device, phone number, or IP address appears across multiple supposedly unrelated accounts, not just whether a single transaction is suspicious.
This network-level analysis is where AI fraud detection in banking adds value that rule-based systems structurally cannot replicate: identifying coordinated signals across a synthetic identity network before the bust-out event occurs.
How to Reduce False Positives in AML Compliance
Reducing the false positive rate in fraud detection is a calibration problem with both technical and organizational dimensions. The technical side gets most of the attention, but the organizational side is often where the actual improvement lives.
On the technical side, the highest-impact changes are:
- Segment your rule sets: Apply different logic to different customer segments. A rule appropriate for retail customers will produce excessive false positives when applied to business accounts with high transaction volumes.
- Use behavioral baselines instead of static thresholds: Rather than flagging every transaction over $10,000, flag transactions that are anomalous relative to that customer's own history and peer group.
- Layer your signals: Combine transaction data with device intelligence, account age, KYC verification level, and behavioral patterns. Each additional signal improves discrimination between legitimate activity and fraud.
- Prioritize feedback loops: Make it operationally easy for analysts to mark cases as confirmed fraud or confirmed legitimate, and ensure those decisions update your model within hours rather than weeks.
On the organizational side, two changes make a consistent difference in practice:
Set explicit false positive rate targets alongside fraud catch rate targets. Most compliance teams track how much fraud they caught but not how many legitimate transactions they disrupted. Adding a false positive rate KPI changes the calibration conversation immediately and gives analysts a clear mandate to escalate when rule-tuning is needed.
Involve analysts directly in rule tuning. The people reviewing alerts have the clearest view of which rule triggers consistently produce non-fraud results. A structured process for analyst feedback to reach the model team shortens the calibration cycle considerably.
The FATF risk-based approach framework is the regulatory context that makes this strategy not just operationally sound but regulatorily expected. FATF recommendations explicitly support proportionate responses to risk, meaning your AML program should apply more scrutiny to higher-risk transactions and less to everything else, which is exactly what well-calibrated AI fraud detection in banking does.
Our broader coverage of AI-powered fraud detection strategy for risk heads covers how false positive reduction fits into a complete fraud operations framework, including governance, tooling, and reporting structures.
The Agentic AI Shift: Moving Beyond Score-and-Review
The next evolution beyond ML scoring is agentic AI, where the system doesn't just score transactions but actively investigates anomalies, gathers corroborating signals, and builds a more complete picture before escalating to a human analyst.
An agentic fraud detection system responding to a flagged transaction might automatically check: Has this device appeared on other accounts? Has the customer made this type of transaction before? Is there open intelligence on this merchant or counterparty? Only after completing that investigation does it either clear the transaction or escalate to an analyst, with a structured summary of its findings already assembled.
This changes the false positive cost in fraud detection at the analyst level. Teams that have adopted agentic investigation workflows find that the cases reaching human review are substantially more likely to represent genuine fraud, because the agentic system pre-filters and pre-investigates the alert queue. Instead of analysts starting from a raw flag with no context, they're reviewing a fully assembled case with supporting evidence already gathered.
Our analysis of how agentic AI fraud agents cut false positives by 80% walks through the architecture and the operational changes involved in this transition, including where the false positive reduction occurs in the workflow and how to measure it.
- False positives in fraud detection occur when a legitimate transaction or customer is flagged as potentially fraudulent.
- Fraud alert fatigue happens when analysts review so many false positives that they begin clearing alerts without adequate scrutiny.
- AI fraud detection uses machine learning models trained on historical transaction patterns to score each transaction's fraud probability in real time, rather than checking it against a fixed list of alert conditions.
- Real-time fraud detection in banking is table stakes now.
- Automated transaction monitoring software has matured considerably.
Onboard Customers in Seconds
Conclusion
The false positive cost in fraud detection is not just an operational inefficiency. It is a strategic problem that affects customer retention, analyst capacity, regulatory standing, and your ability to catch actual fraud. Most institutions know their false positive rates are too high. Fewer have a structured program to reduce them.
The path forward is practical: move from static rule-based systems to ML-driven behavioral analysis, invest in agentic investigation workflows that reduce raw alert volume before it reaches human teams, and set explicit false positive rate targets alongside your fraud catch rate KPIs. When evaluating transaction monitoring software or reconsidering your current platform's configuration, start with this question: what does this system do with the 95% of alerts that aren't fraud? That answer will tell you whether the tool is solving your actual problem or creating a more expensive version of the one you already have.



Share this article