.webp)



Listen To Our Podcast🎧

Introduction
SHAP values explainable AI regulators has become one of the most pressing concerns for compliance officers across banking, fintech, and insurance. When an AI model denies a loan application or flags a digital identity as high-risk, simply pointing to a probability score no longer satisfies examiners. They want to know which features drove the decision, how much each one contributed, and whether the logic holds up under scrutiny. This post breaks down what SHAP values are, how they apply to identity verification fintech and fraud detection workflows, and what your compliance team needs before the next model audit.
- What Are SHAP Values and Why Do Regulators Care?
- How SHAP Values Work in AI-Powered Identity Verification Fintech
- Biometric Identity Verification: Explaining High-Stakes Decisions
- How SHAP Values Support Synthetic Identity Fraud Detection
- Implementing SHAP Values in Your Identity Verification API
Onboard Customers in Seconds
What Are SHAP Values and Why Do Regulators Care?
SHAP stands for SHapley Additive exPlanations, a method rooted in cooperative game theory. For any prediction your model makes, SHAP assigns a contribution value to each input feature. A positive SHAP value for "days since last address change" means that feature pushed the model toward a higher risk score. A negative value pulled the score down.
The math comes from Lloyd Shapley's 1951 work on fair resource allocation in cooperative games. Applied to machine learning, SHAP answers one question: across all possible subsets of input features, how much does each individual feature contribute to the final prediction? That framing maps almost exactly to what financial regulators now require.
The Core Math Behind SHAP, Made Readable
The three properties regulators care about most are:
- Local accuracy: The sum of all SHAP values equals the model output minus the baseline prediction. Every decision accounts for itself mathematically.
- Consistency: If a feature gains more impact after retraining, its SHAP value will not decrease. Attribution is monotonic.
- Missingness: Features absent from the input receive a SHAP value of zero. Nothing is fabricated.
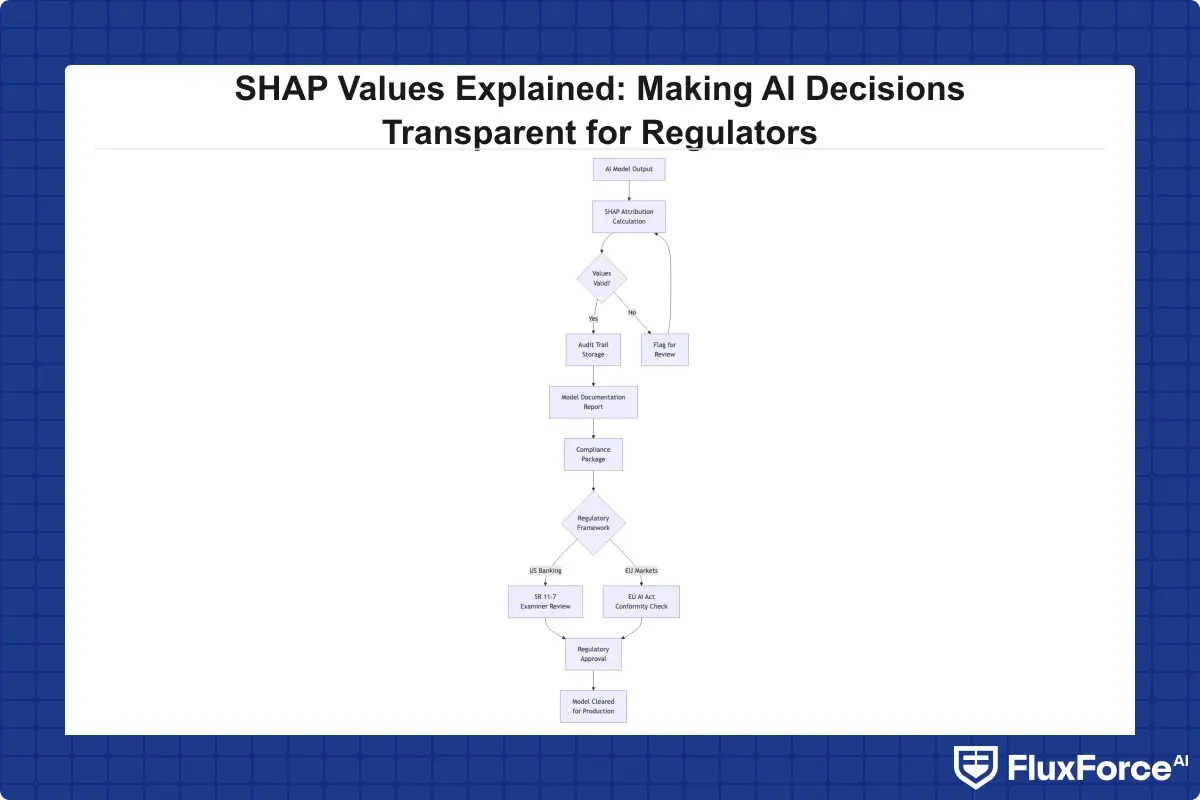
These properties mean SHAP explanations are not just visualizations. They are mathematically defensible attribution statements, which matters when presenting documentation to a model risk examiner or preparing annexes for the EU AI Act.
When Black-Box AI Becomes a Compliance Liability
The Federal Reserve's SR 11-7 guidance requires model risk management programs to document how a model works and validate its conceptual soundness. For deep learning models, tree ensembles, and neural network-based fraud detectors, meeting that standard without explainability tooling is practically impossible.
The EU AI Act goes further for "high-risk" AI systems, a category that explicitly includes credit scoring, digital identity proofing, and fraud detection. Institutions without SHAP values explainable AI tooling in their governance stack face real audit exposure as these requirements take effect across EU member states.
How SHAP Values Work in AI-Powered Identity Verification Fintech
Identity verification fintech relies heavily on ensemble models and neural networks. A typical digital identity proofing pipeline includes a document classifier, a facial comparison model, a liveness detection layer, and a risk scoring module. Each component makes decisions that affect whether a customer gets onboarded or flagged for review.
Feature Attribution in KYC and Credit Decisions
Take a KYC risk scoring model with inputs like document type, issuing country, device fingerprint, IP geolocation, biometric match confidence, and transaction history. SHAP attribution tells you that for a specific customer flagged as high-risk, the biometric match confidence contributed +0.3 to the risk score while the device fingerprint contributed +0.6.
That breakdown lets a compliance analyst say: "The system flagged this customer because the device had no prior history, not because of any document problem." That distinction matters for AML risk checks during policy issuance and for adverse action notices under fair lending regulations.
How Explainability Affects KYC Onboarding Speed
Adding explainability layers does not slow KYC onboarding speed. When SHAP outputs are embedded directly in the review queue, analysts understand within seconds whether a flagged case is driven by a document issue, a biometric anomaly, or a behavioral signal. That context cuts average manual review time from roughly 10 minutes per case to under 3 minutes.
The SHAP computation itself adds 50-200 milliseconds to a typical identity verification API call. The real KYC onboarding speed improvement comes from the decision workflow downstream, not the API response time.
Biometric Identity Verification: Explaining High-Stakes Decisions
Biometric identity verification is one of the highest-stakes AI applications in financial services. When a facial recognition model rejects a customer's selfie, the institution must explain why, both to the customer and to any regulator who asks.
Liveness Detection Fraud and Decision Transparency
Liveness detection fraud involves spoofing biometric systems using printed photos, video replays, or AI-synthesized faces. The models defending against these attacks learn subtle artifacts in image textures and micro-motion sequences that do not translate easily into plain language.
SHAP applied to liveness detection outputs highlights which image regions most influenced the "spoof" or "live" classification. A high SHAP contribution from eye-blink timing combined with a negative contribution from texture consistency tells the review team the model detected unnatural blinking, not image artifacts. That explanation is defensible in a regulatory examination and actionable for investigators.
Deepfake Detection Banking Applications
Deepfake detection banking is moving from best practice to regulatory expectation. The AI-powered fraud detection approaches used by banking risk heads increasingly include deep learning models trained to identify AI-synthesized faces and voices. Without SHAP or comparable attribution methods, validating these models under SR 11-7 is nearly impossible.
Deep SHAP or GradSHAP computes attributions at the pixel or feature-map level, producing a heatmap showing which facial regions drove the deepfake classification. In a banking context, these heatmaps become part of the fraud case file, giving auditors evidence that the AI decision was grounded in genuine visual anomalies.
How SHAP Values Support Synthetic Identity Fraud Detection
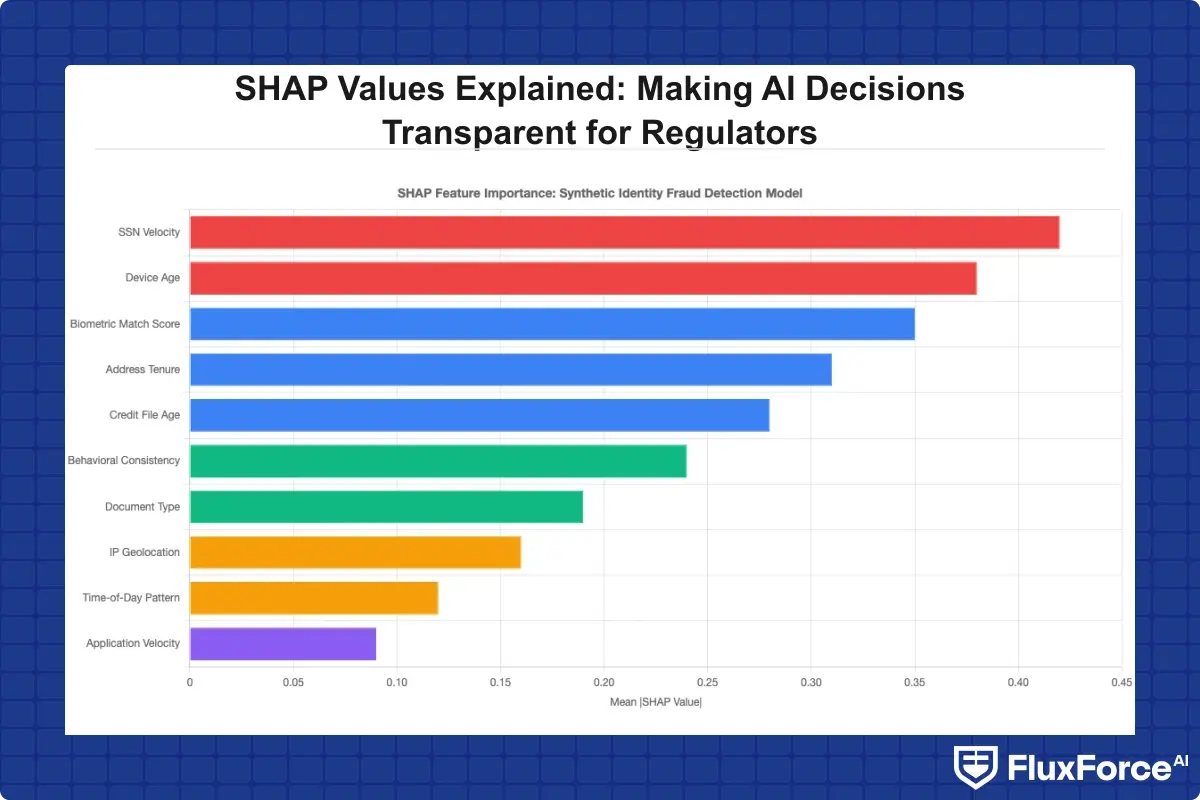
Synthetic identity fraud is the fastest-growing category of financial fraud in the United States, with the Federal Reserve estimating annual losses exceeding $6 billion. Detecting it requires models combining dozens of signals: SSN issuance patterns, credit bureau behavior, device fingerprints, and behavioral biometrics. SHAP makes these combined signals legible to investigators and examiners.
Synthetic identity fraud is the fastest-growing category of financial fraud in the United States, with the Federal Reserve estimating annual losses exceeding $6 billion.
Synthetic Identity Fraud Detection with SHAP
Synthetic identity fraud detection models built on graph-based features are among the most complex in financial services. A synthetic identity shows a slow build-up pattern: thin credit file, no address history, new device, behavioral patterns inconsistent with the claimed demographic profile.
For institutions operationalizing this, detecting synthetic identity fraud in real-time requires SHAP integration at the scoring layer, not just in post-hoc batch analysis. When the model flags a synthetic applicant, the SHAP attribution should be visible in the case management system before the investigator opens the file.
Zero Trust Financial Services and Model Explainability
Zero trust financial services architectures treat every data signal as unverified until proven otherwise. Applying a zero trust security framework to AI model governance means treating model outputs the same way: no score earns trust without attribution evidence. SHAP provides that layer, giving security and compliance teams the evidence chain they need.
Institutions building zero trust security architectures for banking operations are integrating SHAP outputs into continuous monitoring pipelines as model behavior attestation, checking whether feature attribution patterns have shifted over time, not just whether scores are numerically stable.
Implementing SHAP Values in Your Identity Verification API
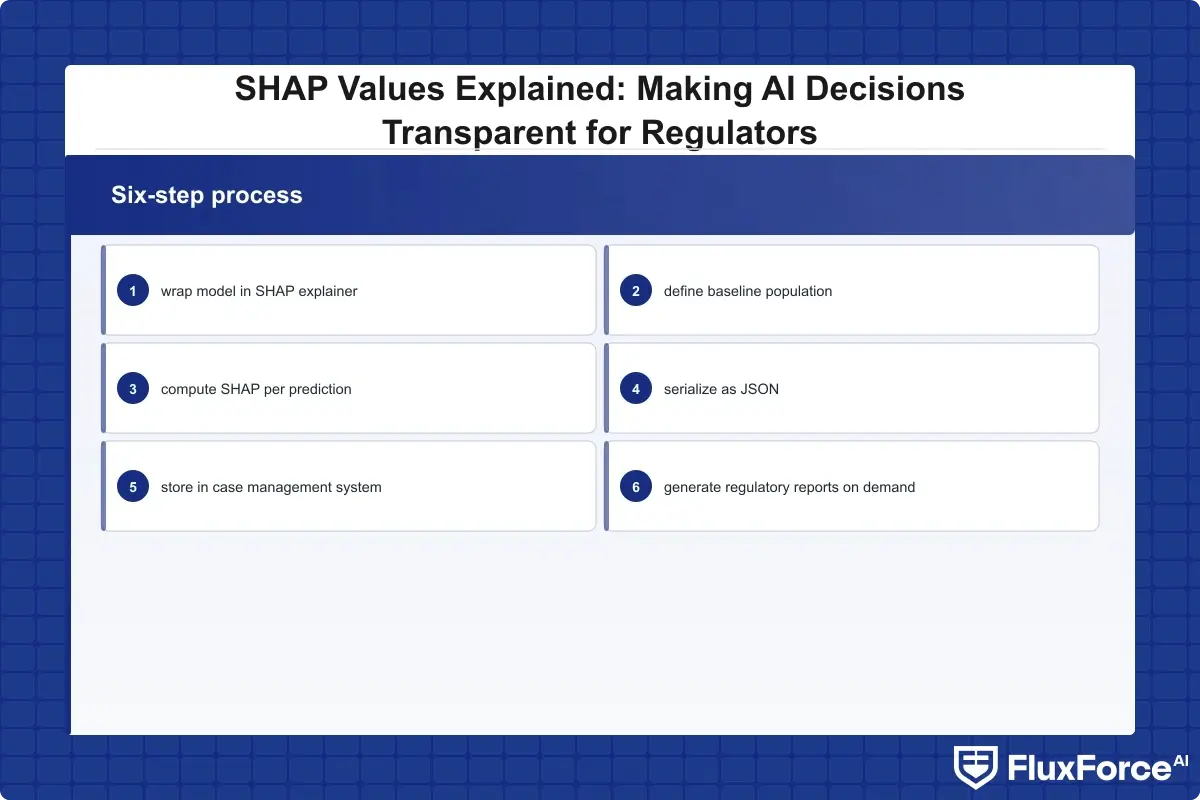
Getting SHAP into a production identity verification API is a different challenge from understanding what SHAP does. Most API integrations treat the AI model as a black box: the API returns a score and pass/fail, and the downstream system acts on that. Adding SHAP changes both the API contract and the data architecture.
Connecting SHAP Outputs to Digital Identity Proofing
Digital identity proofing workflows need SHAP outputs in a structured, machine-readable format that can be stored and retrieved during regulatory examinations. Serialize SHAP values as a JSON object alongside the model score: each input feature gets a key with its SHAP value. This data lives in your case management system and is retrieved during audits.
For institutions using a layered KYC/AML automation approach, SHAP outputs can feed directly into the routing engine determining case disposition: manual review, straight-through processing, or enhanced due diligence. The SHAP value for biometric match confidence might trigger a different routing path than the same numerical score driven primarily by device risk.
Zero Trust Security Framework for AI Model Audits
A zero trust security framework applied to AI governance means every model version must re-earn trust through evidence. SHAP values allow validators to detect whether feature attribution patterns have shifted between model versions, an early indicator of drift or data contamination before performance metrics visibly degrade.
The NIST AI Risk Management Framework explicitly calls for monitoring AI systems for behavioral drift. SHAP-based drift detection tracks the distribution of feature attributions over time, giving compliance teams a quantitative early-warning signal that the model is still making decisions for the right reasons.
How Do SHAP Values Help Meet Regulatory Requirements?
The honest answer is that SHAP values are necessary but not sufficient for regulatory compliance. They provide the feature attribution evidence regulators ask for, but they need to sit inside a broader model risk management program that includes validation, documentation, and ongoing monitoring. The SHAP values explainable AI regulators request is one component of that program.
SR 11-7, EU AI Act, and Explainable AI Requirements
The Federal Reserve's SR 11-7 guidance requires institutions to understand, validate, and document their models. For AI-driven decisions, SHAP handles the "understand" component. SHAP stability testing checks whether attribution patterns are consistent across data slices and time periods, a form of conceptual soundness verification that directly maps to SR 11-7 validation requirements.
The EU AI Act's requirements for high-risk AI systems align closely with what SHAP delivers: explanation of decisions to affected persons, bias testing across demographic groups, and evidence of human oversight. Institutions subject to both US and EU regulations will find SHAP outputs address a significant portion of both frameworks' technical documentation requirements.
Building Audit Trails That Satisfy Examiners
Regulators increasingly expect institutions to retain SHAP values for individual decisions, not just aggregate model documentation. At high identity verification API volumes, per-prediction SHAP storage adds real overhead.
A practical approach: store full SHAP vectors for high-risk decisions that triggered manual review or adverse action, and store only SHAP summary statistics for low-risk straight-through decisions. This balances auditability with storage cost and aligns with risk-proportionate compliance automation approaches that regulators increasingly accept in place of blanket retention requirements.
What to Watch For: Common Pitfalls with SHAP in Regulatory Reporting
SHAP is not perfect. Presenting it to examiners without understanding its limitations introduces its own compliance risk.
SHAP values are local explanations. They explain why the model made this specific prediction. They do not indicate whether the model is fair across a population. Global SHAP methods, such as summary plots and beeswarm charts, are required separately for bias testing under fair lending and EU AI Act frameworks.
Feature correlation distorts attribution. When two features are highly correlated, such as biometric match confidence and liveness score, SHAP can split attribution between them in ways that appear arbitrary. Reviewers need calibration on this before drawing conclusions from individual SHAP values.
SHAP can be manipulated. Research has demonstrated that adversarial inputs can alter SHAP explanations while leaving model outputs unchanged. For institutions using SHAP in fraud investigation workflows, this needs explicit treatment in model governance documentation.
Computation speed varies by method. TreeSHAP is fast enough for real-time use. KernelSHAP is substantially slower. For a real-time identity verification fintech pipeline processing thousands of verifications per minute, selecting the wrong SHAP variant will break SLA commitments.
- SHAP stands for SHapley Additive exPlanations, a method rooted in cooperative game theory.
- Identity verification fintech relies heavily on ensemble models and neural networks.
- Biometric identity verification is one of the highest-stakes AI applications in financial services.
- Synthetic identity fraud is the fastest-growing category of financial fraud in the United States, with the Federal Reserve estimating annual losses exceeding $6 billion.
- Getting SHAP into a production identity verification API is a different challenge from understanding what SHAP does.
Onboard Customers in Seconds
Conclusion
Explainable AI and SHAP values are no longer confined to data science teams. Regulators in both the US and EU now treat them as governance requirements for every institution running AI-driven credit, fraud, or identity decisions. SHAP values explainable AI regulators demand has moved from a specialist topic to a board-level accountability question, and institutions that have embedded it into model governance workflows hold a meaningful compliance advantage.
The technical foundation is mature. SHAP integrates cleanly with the frameworks used in biometric identity verification, synthetic identity fraud detection, and digital identity proofing. The harder work is operational: building data pipelines, audit trail storage, and reviewer training that convert SHAP outputs into defensible compliance evidence. Start with your highest-risk models, map SHAP outputs to the specific regulatory questions you will face, and treat explainability as a design requirement from day one rather than a retrofit.



Share this article