.webp)



Listen To Our Podcast🎧

Human in the loop AI compliance isn't a checkbox exercise. For banks, fintechs, and insurers running AI agents across fraud, AML, and credit decisioning, the real question isn't whether humans should stay in the loop. It's exactly which decisions require a person's sign-off, and how to design workflows so that approval doesn't become a bottleneck that kills the efficiency AI was supposed to deliver. AI agents in financial services are making thousands of decisions per minute. Getting this balance right is what separates institutions that pass regulatory audits from those that spend the next 18 months in remediation.
This post maps out where full automation makes sense, where it creates regulatory liability, and what a genuinely compliant AI architecture looks like in 2026.
Why Human in the Loop AI Compliance Is Not Optional
Regulators in every major jurisdiction have made one thing clear: AI systems involved in high-stakes financial decisions must have documented human oversight mechanisms. The EU AI Act classifies credit scoring, AML screening, and insurance risk assessment as high-risk AI applications, meaning they require transparency, human review capabilities, and audit logs by law. The NIST AI Risk Management Framework similarly identifies human oversight as a core governance control for AI systems operating in consequential domains.
This isn't theoretical risk. In 2024, several European banks received supervisory findings specifically for deploying AI decisioning systems without adequate human review trails. The fines weren't enormous in most cases, but the remediation costs were substantial. Retrofitting human-in-the-loop controls into production AI systems is far harder than building them in from the start, and regulators know it.
The Regulatory Pressure Behind Human Oversight
The EU AI Act requires that high-risk AI systems allow human intervention, provide explanations for individual decisions, and maintain complete audit trails. For financial institutions, this translates into three hard requirements: a person must be able to override any AI decision, the system must explain why it reached a conclusion in plain language, and every decision must be logged with enough context to reconstruct the reasoning months later.
What makes this difficult is volume. A mid-sized bank might process 200,000 card transactions per hour. Putting a human in front of every one isn't possible. So the system design has to be smarter than a binary "human or AI" choice. It needs to be a calibrated threshold system.
When AI Gets It Wrong: High-Stakes Errors in Finance
AI errors in financial services follow a consistent pattern: models fail hardest on edge cases that weren't well-represented in training data. Synthetic identity fraud is a clear example. Models trained primarily on historical fraud patterns often miss novel synthetic identities in real time, a problem covered in depth in our piece on detecting synthetic identity fraud in real-time.
The failures cluster around exactly the cases that matter most: high-value transactions, unusual customer profiles, and fraud patterns that emerged after the model's training cutoff. This is precisely why no AI system should operate without a human escalation path for low-confidence or high-stakes decisions.
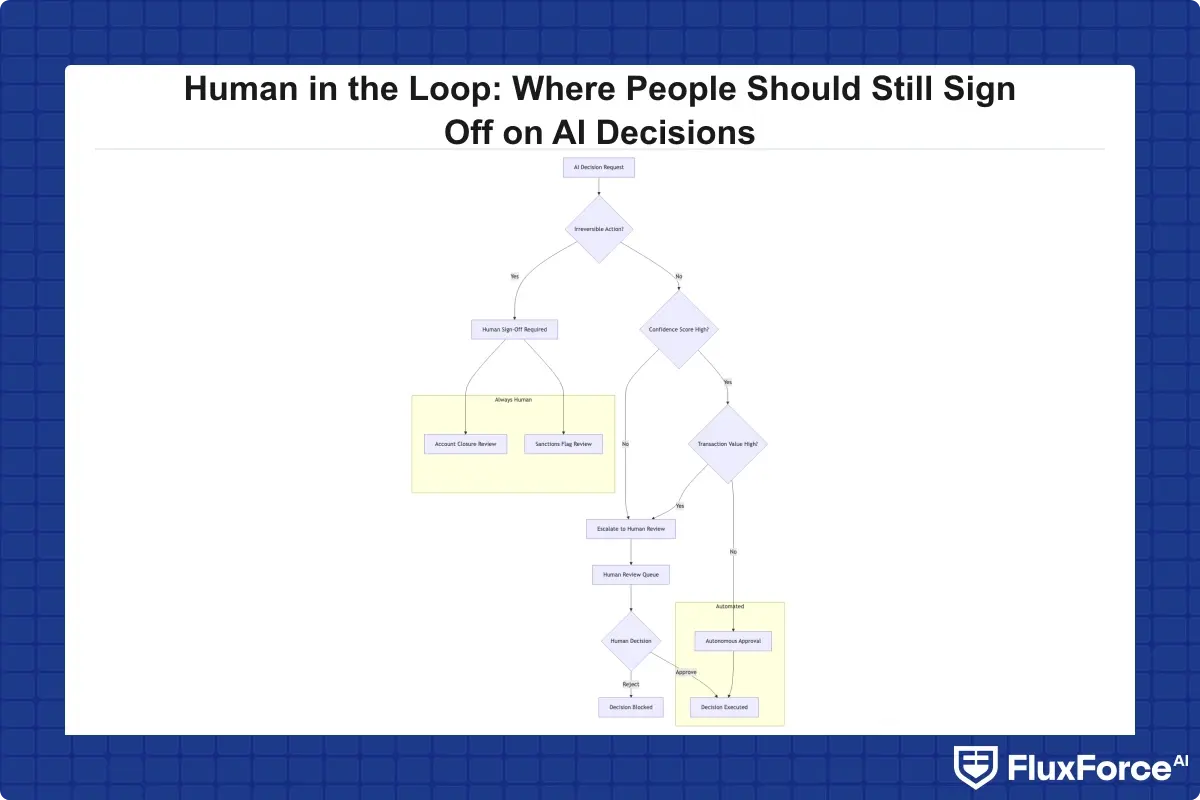
Where AI Should Operate Autonomously vs. Where Humans Must Step In
Configurable AI autonomy is the design principle that resolves the volume problem. Define clear thresholds at which AI operates without human intervention, and equally clear triggers that escalate a case to a reviewer. Getting those thresholds right means knowing your model's error rates by decision type, not just its overall accuracy number.
AI Agent Fraud Detection: Speed Matters More Than Oversight Here
For real-time fraud decisioning on individual transactions, AI agent fraud detection works well autonomously, but only when model confidence is high. A fraud model that flags a transaction at 97% confidence, on a pattern it has processed tens of thousands of times before, doesn't need a human to confirm it. Blocking the transaction in under 300 milliseconds is the entire point. Routing it to a review queue instead means the fraud succeeds.
Our analysis of how agentic AI fraud agents cut false positives by 80% shows that the efficiency gains in fraud detection come precisely from removing humans from high-confidence, high-frequency decisions. The AI is faster, more consistent, and statistically more accurate than a human reviewer working through a queue late at night. That's fine, as long as the confidence threshold is set correctly and reviewed periodically.
Human in the Loop AI Banking: The Cases That Need Eyes
Human in the loop AI banking becomes critical in four specific scenarios. First, when model confidence falls below your defined threshold, with most implementations setting this between 70% and 80%. Second, when the transaction or account value is above a defined ceiling. Third, when the AI's decision would have irreversible consequences: account closure, loan rejection, or sanctions flagging. Fourth, when the case has regulatory reporting implications, such as a Suspicious Activity Report, which should always carry a human signatory.
These triggers need to be explicit rules in your workflow configuration, not informal guidelines left to individual team members. When a regulator asks why a specific case went to human review rather than auto-resolved, you need a logged rule that answers that question, not someone's recollection.

The Black Box Problem: Why Explainable AI Compliance Matters
Black box AI compliance risk is the issue regulators raise most consistently during AI governance reviews. When an AI system can't explain its decisions, three things happen simultaneously: your compliance team can't verify the decision was lawful, your customer can't meaningfully challenge the outcome, and your auditor can't assess whether the model has drift or bias problems.
Explainable AI compliance isn't just about regulatory optics. It's about catching model drift, demographic bias, and data quality issues before they become systemic. Explainable AI finance requires that you can answer "why did this model reach this conclusion?" for any individual decision, at the time it was made, using the evidence available at that moment.
SHAP Values Explained for Regulators
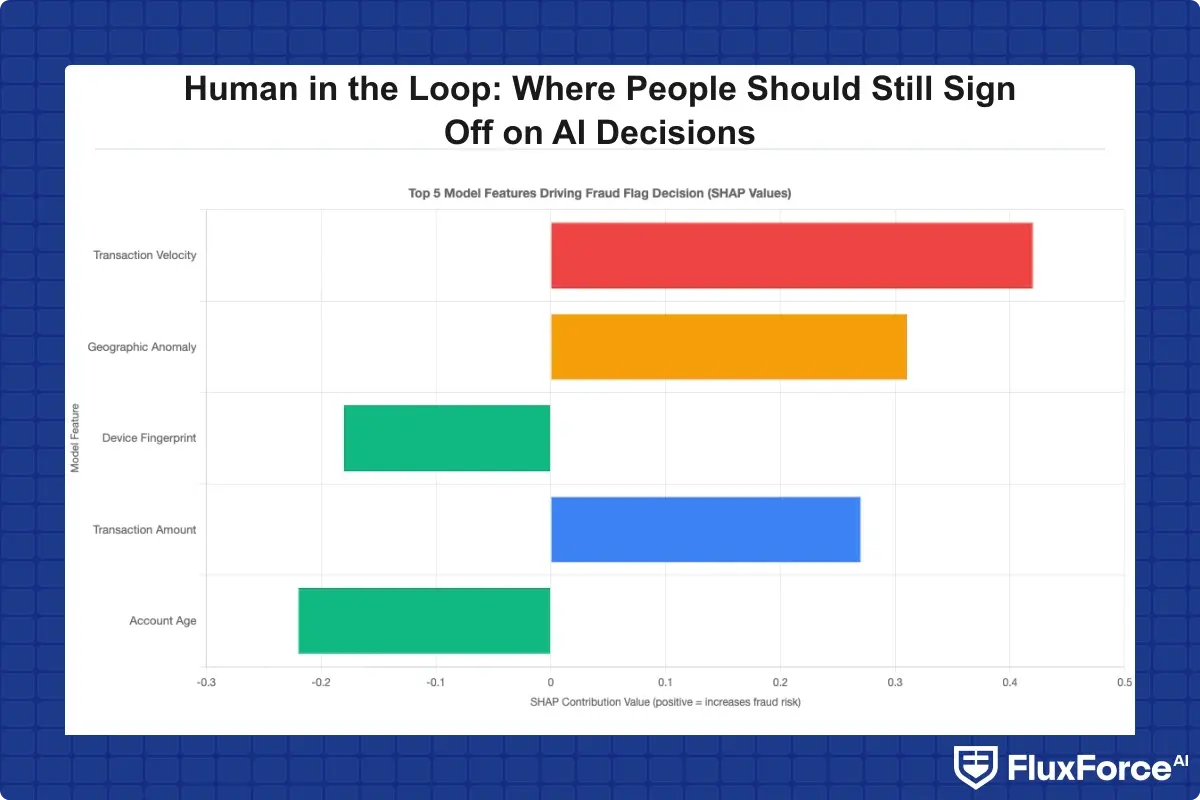
SHAP values (Shapley Additive Explanations) are the most widely accepted method for making individual AI predictions interpretable. The concept draws from cooperative game theory: each input feature receives a contribution score for a specific prediction, showing how much it pushed the outcome in either direction.
In practice, shap values explained for regulators means presenting a compliance officer with something concrete: "This loan application was declined. The primary factors were debt-to-income ratio (+0.42 risk contribution), recent missed payment history (+0.31), and a thin credit file (+0.18). Together they pushed the risk score above the approval threshold." That's something a regulator can evaluate against fair lending standards. A decision log that says "model score: 0.71, threshold: 0.65, declined" tells an examiner almost nothing useful.
XAI Fraud Detection and What Auditors Actually Ask For
XAI fraud detection, applying explainability methods specifically to fraud scoring models, has shifted from a differentiator to an examination expectation. During a regulatory audit, examiners ask: can you show the top three factors that drove this specific fraud flag? Can you demonstrate the model doesn't rely on proxy variables for protected characteristics? Can you show consistent treatment of similar transactions across time?
AI model explainability for regulators isn't satisfied by a one-time model explanation report. It requires logging explanation data at inference time, for every decision, in a format that can be queried months later. The comparison between AI and traditional fraud detection approaches covers how explainability requirements differ between rule-based and machine learning systems, which is worth reading if you're evaluating the trade-offs for your institution.
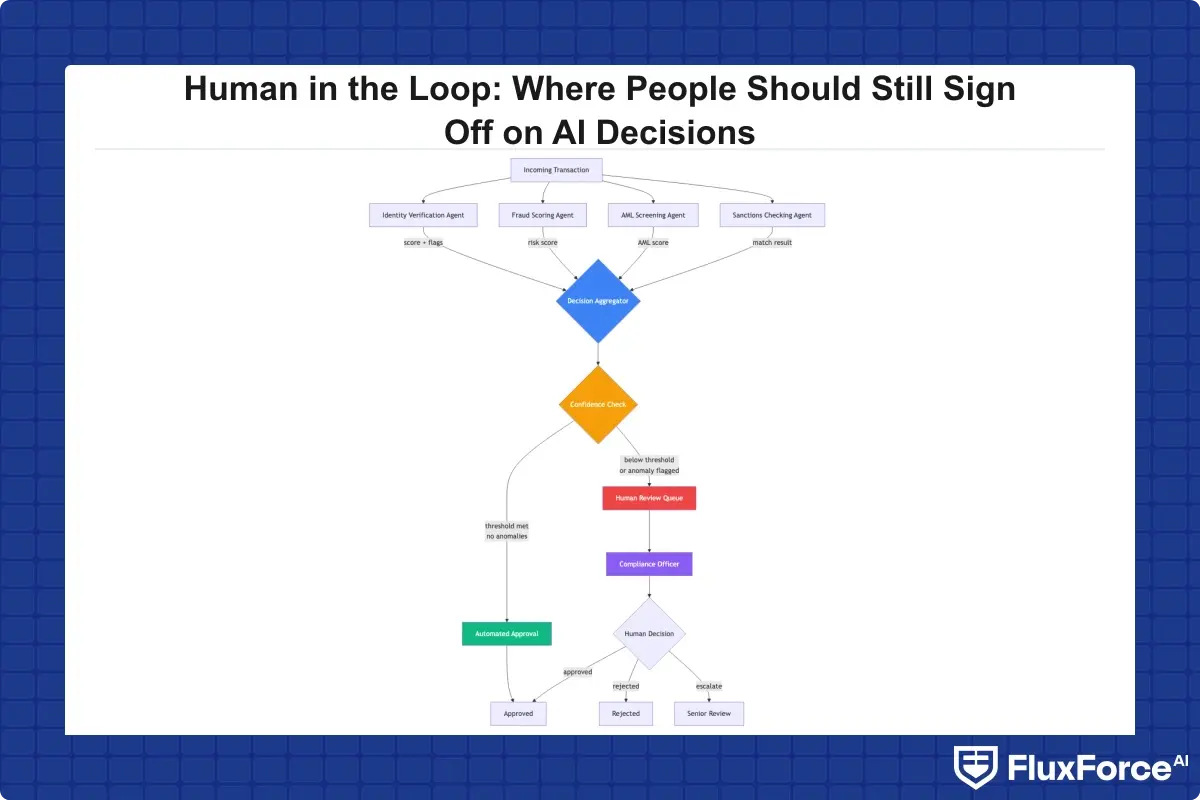
Human in the Loop AI Compliance and Multi-Agent Systems
The shift toward multi-agent AI systems in financial services creates a new oversight challenge. When a single model makes a decision, tracing it is straightforward. When a multi-agent AI system involves three or four specialized agents, one for identity verification, one for transaction scoring, one for AML screening, one for sanctions checking, each contributing to a final outcome, the audit trail gets complicated fast.
AI agents in financial services are increasingly coordinated pipelines, not standalone models. That's actually an advantage for oversight when the architecture is designed correctly: each agent's output can be logged independently, creating granular transparency that a monolithic model doesn't provide. But only if that logging is built in from the start, not added as an afterthought.
Multi-Agent AI System Architecture in Financial Services
A well-designed multi-agent AI system in banking routes decisions through specialized agents that each produce a scored output, with a meta-layer that aggregates these into a final recommendation. The human-in-the-loop control sits at the meta-layer: if the aggregate recommendation crosses an escalation threshold, or if any individual agent flags low confidence, the case routes to a human review queue.
The fraud compliance identity platform that performs best in practice separates concerns clearly. Fraud scoring, identity verification, and regulatory screening operate as distinct agents with distinct accountability chains, then recombine at the decision layer. This separation makes it possible to audit each component independently when questions arise during examination.
AI Audit Trail Automation: The Paper Trail Regulators Expect
AI audit trail automation converts a multi-agent system from a black box into a defensible compliance record. Every agent invocation should log the input it received, the model version it used, the output it produced, the confidence score, and the timestamp. For decisions that escalated to human review, the log must also capture who reviewed the case, when, and what decision they reached.
This isn't bureaucratic overhead. When a regulator asks about a specific transaction from eight months ago, you need to reconstruct the full decision chain in under ten minutes. Our post on rolling out regulatory compliance agents in 90 days covers how to build this audit infrastructure into an agentic deployment from the ground up.
Point Solutions vs Platform Financial Services: The Oversight Problem
One factor that makes human-in-the-loop controls genuinely hard to implement is fragmented tooling. The point solutions vs platform financial services debate has direct implications for AI governance: if your fraud detection system, AML screening tool, identity verification service, and sanctions checker are separate vendors with separate dashboards and separate logs, maintaining coherent human oversight becomes operationally painful.
Reviewers toggle between four different interfaces to understand a single case. Audit trails exist in four different systems that don't share a common format. Escalation workflows span tools that don't communicate with each other. Vendor consolidation in fintech isn't just a cost argument. It's a compliance argument.
Vendor Consolidation Fintech and Control Gaps
Vendor consolidation in fintech addresses a specific problem: when AI decisioning is spread across multiple point solutions, control gaps appear at the seams. A transaction might clear the fraud engine before the AML check completes. An identity verification result from one vendor might conflict with a risk score from another, with no automated logic to resolve the conflict. A human reviewer working the case can't easily see the full picture.
Each additional vendor in the stack adds integration complexity, and integration complexity is where audit trails break down. A missed log entry or a timing gap between systems is exactly what regulators identify as a control weakness during examination.
Unified Risk Platform as the Answer
A unified risk platform solves this by consolidating fraud, compliance, and identity intelligence into a single decision engine with a single audit log. Human review queues draw from one system. Escalation rules are defined once and applied consistently. The audit trail is complete by design rather than assembled after the fact from multiple data exports.
The ai security operations platform concept extends this further: not just unifying risk decisioning, but providing security and compliance teams with a single operational view across fraud, AML, identity, and access controls. For institutions currently managing these functions across separate vendor tools, this architectural shift is the difference between a defensible compliance posture and a stitched-together one that only holds together until the first examiner looks closely.
Configurable AI Autonomy: Building the Right Approval Workflows
Configurable AI autonomy means the escalation rules, approval thresholds, and autonomy limits can be adjusted by your risk and compliance team without a code deployment. This matters because the right thresholds change: regulatory guidance evolves, fraud patterns shift, and model performance drifts over time.
When escalation rules are hardcoded into the application, every threshold adjustment requires an engineering release. That creates a change management bottleneck that makes compliance teams dependent on engineering backlogs to respond to updated regulatory guidance. The right design puts threshold configuration in the hands of risk and compliance through a governed configuration layer they control directly.
Fraud Compliance Identity Platform Design Principles
The fraud compliance identity platform that survives regulatory scrutiny is built on three principles. First, every autonomous decision must carry a logged rationale, not just an outcome. Second, escalation to human review must be triggered by explicit, auditable rules, not by implicit model behavior. Third, human decisions must be logged at the same level of detail as AI decisions, so the complete review process is visible and auditable end to end.
These principles apply whether you're running a single AI model or a multi-agent pipeline. For context on how they translate into specific compliance workflows, our breakdown of manual compliance vs. AI automation best practices is worth reading alongside this post.
When to Escalate vs. Auto-Approve: Practical Thresholds
The right thresholds are institution-specific and should be calibrated against your own operational data. That said, most effective implementations share a common pattern. Auto-approval applies when model confidence exceeds a defined minimum (commonly 85-90%), the transaction value is below a defined ceiling, and no secondary risk flags are active. Everything else routes to a reviewer queue, prioritized by the combination of risk score and transaction value.
Risk teams using AI-powered fraud detection software with configurable autonomy define their own escalation logic without touching code, so adjusting thresholds to reflect new fraud patterns or updated regulatory guidance takes hours rather than sprint cycles. That speed matters most when a novel fraud vector emerges during a peak transaction period and you can't wait two weeks for a release.
Human in the Loop AI Banking: What Regulators Expect in 2026
Regulatory examinations have gotten more specific. Generic "we have AI governance" answers don't satisfy modern examiners. What regulators actually ask for in 2026: can you produce the model card for your fraud detection model? Is model performance monitored on an ongoing basis, with automated alerts for drift? Can you demonstrate that a human reviewed the AI's recommendation before this SAR was filed?
The FATF guidance on AI and financial crime compliance emphasizes that institutions must demonstrate model governance, explain AI decisions in terms of AML risk factors, and maintain human accountability for regulatory filings. These aren't aspirational standards. They're examination criteria that financial intelligence units across multiple jurisdictions are actively applying to institution reviews right now.
AI Model Explainability and Regulatory Expectations
Explainable AI compliance has moved from a best practice to an examination requirement in most jurisdictions. The EU AI Act focuses on transparency and the individual's right to explanation. US regulators including the OCC and CFPB focus on model risk management frameworks and fair lending implications. The core requirement is consistent across all of them: be able to show your work.
AI model explainability for regulators requires building explainability into the production inference pipeline, not generating post-hoc explanations from a separate analysis tool. The explanation that satisfies an examiner is the one generated at decision time, from the model version that actually made the call. Reconstructed explanations produced after the fact are not accepted as equivalent by most regulatory bodies.
AI Security Operations Platform as a Compliance Foundation
The ai security operations platform category has emerged because compliance and security are now deeply intertwined in financial services. Fraud is a security problem. AML is a compliance problem. Identity verification sits at the intersection of both. A platform that unifies these with shared audit infrastructure, shared escalation workflows, and shared explainability tooling gives compliance and security teams the visibility they need to satisfy regulators and respond to incidents quickly.
For institutions evaluating this architectural transition, the question isn't whether to consolidate but how fast to move. The compliance and operational benefits of a unified risk platform over fragmented point solutions compound over time, particularly as regulatory requirements around AI governance in financial services become more prescriptive each year.
Onboard Customers in Seconds
Conclusion
Human in the loop AI compliance is an architecture problem, not a policy problem. The institutions that get this right aren't the ones with the longest manual review checklists. They're the ones that have identified exactly which decisions require human sign-off, built escalation workflows that are explicit and auditable, and invested in explainable AI finance so that every decision can be reconstructed on demand.
The move from point solutions to a unified risk platform, combined with configurable AI autonomy and AI audit trail automation, is what makes compliant AI decisioning achievable at scale. Retrofitting oversight controls onto fragmented systems after a regulatory finding costs significantly more and delivers far less than building human-in-the-loop controls in from the start.
Begin with the decisions that matter most: high-value transactions, irreversible outcomes, regulatory filings. Get the human review workflow solid in those categories first. Then use what you learn to calibrate the autonomy thresholds for the high-confidence, high-frequency decisions that AI should handle without interruption.



Share this article