.webp)




Introduction
Choosing between rule based vs AI fraud detection is one of the most consequential decisions a risk team will make in the next 12 months. Global payment fraud losses crossed $40 billion in 2023, and legacy approaches are struggling to keep up with how fast fraud patterns shift. Rule-based systems still run the show at many banks and fintechs, but AI-powered transaction monitoring is gaining ground fast. Neither is a silver bullet. This post cuts through the vendor noise to give you an honest, data-driven look at how each approach works, where each breaks down, and what the real cost difference looks like when you factor in false positives, alert fatigue, and compliance exposure.
Global payment fraud losses crossed $40 billion in 2023, and legacy approaches are struggling to keep up with how fast fraud patterns shift.
- What Is AI Fraud Detection?
- How Rule-Based Systems Work
- Rule Based vs AI Fraud Detection: Core Differences
- False Positive Rates: Rule Based vs AI Fraud Detection
- Real-Time Fraud Detection in Banking
Onboard Customers in Seconds
What Is AI Fraud Detection?
AI fraud detection uses machine learning models, neural networks, and behavioral analytics to identify suspicious transactions and account activity in real time. Instead of matching transactions against a fixed set of rules, AI models learn from historical fraud patterns and continuously update as new data arrives.
In practice, most AI fraud detection systems combine several techniques:
- Supervised learning: Models trained on labeled fraud and non-fraud transactions to predict the likelihood of fraud on new activity
- Unsupervised learning: Anomaly detection that flags behavior deviating from a user's own baseline, without needing labeled examples
- Graph analytics: Identifying hidden relationships between accounts, devices, and merchants that signal organized fraud rings
- Natural language processing: Parsing transaction descriptions and documents to surface suspicious patterns
For banks and fintechs, AI fraud detection in banking often means running these models across millions of transactions per day, scoring each one in milliseconds, and routing only the highest-risk cases to human reviewers.
The practical difference from rule-based systems: AI models find the patterns you didn't think to write rules for yet.
How Rule-Based Systems Work
Rule-based fraud detection applies a predefined set of logic to every transaction. A rule might say: flag any wire transfer over $9,999 from a new account, or block transactions where the billing address doesn't match the shipping country for orders above $500.
These systems work well when fraud follows predictable, stable patterns. They're fast to implement, auditable by compliance teams, and easy to explain to regulators. There's no model explainability problem with a rule; you can read exactly why a transaction was flagged.
The catch is that rules are static. Fraudsters learn which thresholds trigger alerts and stay just below them, a technique called structuring in AML contexts. A rule that caught 90% of a fraud type last year may catch 40% this year once criminals adapt. Adding more rules creates alert fatigue: analysts spend their day clearing false positives instead of investigating real threats.
Most established banks run hundreds of rules in their transaction monitoring software. Industry data from the ACFE shows that fewer than 10% of transaction monitoring alerts lead to a confirmed fraud finding in many institutions, a ratio that's simply not sustainable as transaction volumes grow.
Rule Based vs AI Fraud Detection: Core Differences
The gap between rule based vs AI fraud detection isn't about speed or technology alone. It's about adaptability.
Here's how the two approaches compare across the metrics that matter most to risk teams:
| Metric | Rule-Based | AI / ML |
|---|---|---|
| Detection of known fraud patterns | Excellent | Excellent |
| Detection of novel or evolving fraud | Poor | Good to Excellent |
| False positive rate | High (typically 95-99% of alerts) | 50-80% reduction possible |
| Explainability for regulators | High | Variable (depends on model type) |
| Time to deploy new detection logic | Fast (write the rule) | Slower (needs training data) |
| Ongoing maintenance burden | High (rule governance) | Moderate (model retraining) |
| Cost at scale | Increases linearly | More stable at volume |
| Adapts to new fraud patterns automatically | No | Yes |
The false positive figure is where most risk teams feel the pain first. When 99% of flagged transactions are legitimate, your team is spending 99 cents of every compliance dollar on non-fraud investigation. That ratio doesn't hold at scale.
When 99% of flagged transactions are legitimate, your team is spending 99 cents of every compliance dollar on non-fraud investigation.
For structured regulatory requirements like sanctions screening and PEP checks, rule-based logic is still the right primary tool. For behavioral and transactional fraud where patterns shift constantly, AI holds a clear advantage. You can see a detailed breakdown of how rule based vs AI fraud detection approaches differ in practice across real institution deployments.
False Positive Rates: Rule Based vs AI Fraud Detection
False positives are the hidden tax of fraud detection. A blocked legitimate transaction doesn't just cost the processing fee; it costs customer trust, potential churn, and analyst time that could go toward real investigations.
Put real numbers on it. A mid-size bank processing 1 million transactions per month with a 1% alert rate generates 10,000 alerts. If 98% are false positives (common for rule-based systems), analysts review 9,800 legitimate transactions and only 200 real fraud cases. At $25 per alert investigation, that's $245,000 per month spent investigating non-fraud activity.
AI systems don't eliminate false positives, but research from McKinsey shows financial institutions using ML-powered monitoring can reduce false positives by 50-70% while improving fraud catch rates. Some teams report reductions beyond 80% after tuning models on institution-specific historical data.
Fraud alert fatigue is real and underestimated. When analysts see hundreds of false positives daily, the psychological tendency is to batch-clear alerts without deep review. That's how real fraud slips through, not because the system missed it, but because the reviewer burned out on non-fraud cases. Reducing false positives with AI doesn't just save money; it restores analyst attention to cases that actually require judgment.
Our analysis of how agentic AI fraud agents reduce false positives found institutions that deployed AI fraud agents cut false positive volumes by up to 80% within 90 days, freeing compliance resources for strategic review work rather than queue management.
Real-Time Fraud Detection in Banking
Real-time fraud detection means scoring a transaction and making an allow-or-block decision in under 300 milliseconds, before the payment clears. Rule-based systems can achieve this speed; checking a list of rules is computationally inexpensive.
But real-time detection with rules has a built-in ceiling: it's only as good as the rules already written. If a new fraud vector emerges, your real-time system won't catch it until someone writes a rule for it. That gap can span weeks or months in organizations with complex rule governance processes.
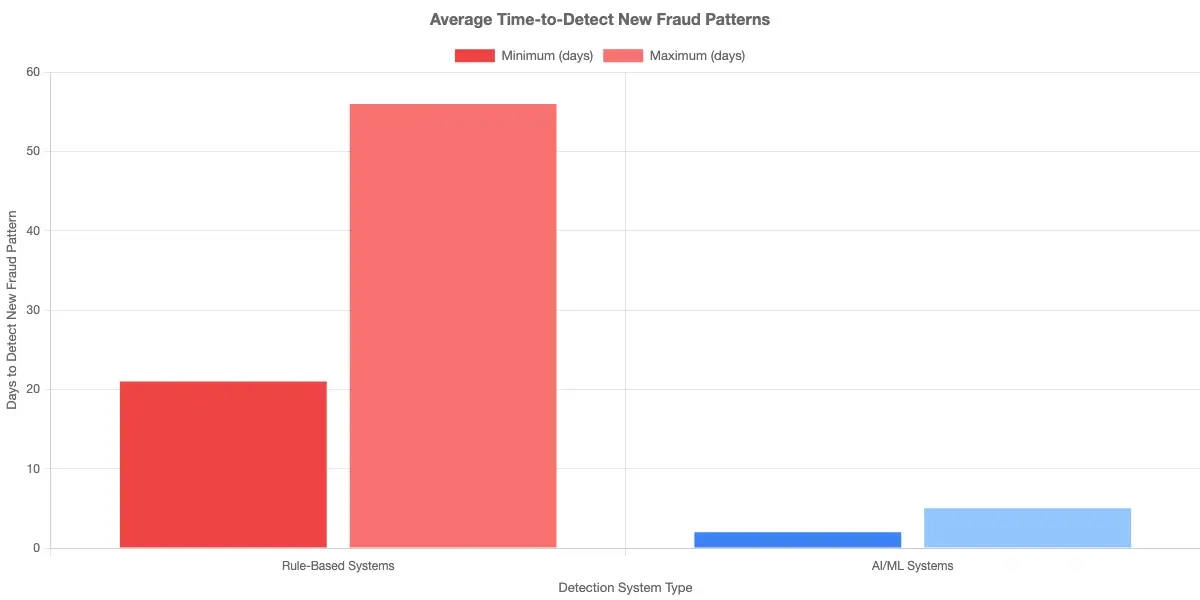
AI-based real-time fraud detection scores each transaction against a model trained on behavioral baselines, device fingerprints, network graph features, and historical fraud patterns. When a transaction deviates from what's expected for that user, device, and merchant combination, the model flags it regardless of whether a specific rule covers the scenario.
For banks running real-time fraud detection, the scoring architecture typically looks like this:
- Transaction initiated
- Features extracted (amount, device, location, time, merchant category, velocity)
- ML model scores transaction risk on a 0-100 scale
- High-risk scores trigger friction (3DS challenge, manual review, or block)
- Borderline scores route to analyst queue
- Low-risk scores pass through
The key advantage: step 3 happens in under 100ms. The problem of synthetic identity fraud in real-time detection illustrates this clearly: synthetic identities built up over months look completely legitimate to rule-based systems until the bust-out moment arrives.
Synthetic Identity Fraud: Why AI Has the Edge
Synthetic identity fraud, which combines real and fabricated data to construct a new identity, now accounts for roughly 85% of identity fraud losses in the United States, according to Federal Reserve research on payment system security. Rule-based systems are nearly blind to it.
Synthetic identity fraud, which combines real and fabricated data to construct a new identity, now accounts for roughly 85% of identity fraud losses in the United States, according to Federal Reserve research on payment system security.
The reason is that synthetic identities behave perfectly during their build-up phase. They establish credit slowly, build a payment history, and look like good customers for 12-18 months before the bust-out. No velocity rule or amount threshold catches this, because the fraud is in the identity construction, not in any individual transaction pattern.
AI models trained on graph features catch synthetic identities by examining relationships: which devices multiple customers share, which addresses appear across dozens of accounts, which SSNs show date-of-birth inconsistencies across bureau pulls. These signals are invisible to a rule but detectable by a graph neural network processing millions of account relationships simultaneously.
For synthetic identity fraud specifically, the rule based vs AI fraud detection question has a definitive answer. Rules alone won't scale to this threat at any practical level of accuracy.
Transaction Monitoring Cost and Software Choices
Transaction monitoring cost is a real concern, particularly for mid-market institutions that don't have the engineering resources of a large bank. Here's a realistic breakdown.
Rule-based transaction monitoring platforms such as NICE Actimize, FIS MANTAS, and Oracle Financial Services typically run $200,000 to $2M+ annually depending on transaction volume, plus significant internal headcount for rule management and alert triage.
AI-native transaction monitoring platforms like Sardine, Unit21, Hawk AI, and Feedzai typically price on a per-transaction or per-account basis, often running $0.001 to $0.005 per transaction at volume. For an institution processing 50 million transactions per month, that's $50,000 to $250,000 monthly before implementation and integration costs.
The honest caveat on total cost of ownership: AI systems require data engineering work, model validation for regulatory review, and ongoing governance documentation. The ROI case depends heavily on your current false positive rate and analyst headcount. If you're running 95%+ false positive rates and paying analysts to clear queues all day, the math usually favors AI within 12-18 months of deployment.
On the sardine vs unit21 question: Sardine has historically been stronger on device intelligence and behavioral biometrics, making it better suited for account takeover and payment fraud prevention. Unit21 offers a more flexible rules-plus-ML hybrid that compliance teams find easier to govern alongside existing regulatory requirements.
For insurers evaluating automated transaction monitoring, the considerations are similar but extend to claims payment workflows and policy payment security, where payment gateway security strategies often intersect with fraud detection requirements.
Rule Based vs AI Fraud Detection: Making the Right Call
Most institutions don't face a binary choice between rule based vs AI fraud detection. The practical answer for most risk teams is a layered approach that uses both:
- Rules as the first filter: sanctions lists, PEP screening, hard velocity limits, and regulatory thresholds applied regardless of ML output
- ML models as the primary scoring layer: behavioral analytics, anomaly detection, and pattern recognition across the full transaction context
- Human review as the final layer: for borderline and high-value cases, with AI reducing queue volume so analysts focus on genuine ambiguity
The organizations that reduce fraud losses most effectively run rules for compliance certainty and AI for adaptive detection. They use both rule-based and AI approaches together to address false positives rather than treating the decision as either/or.
If you're starting from a purely rule-based system, the migration typically takes 6-18 months: data preparation, model training on historical fraud labels, shadow deployment where ML runs alongside rules without taking action, validation, and gradual threshold tuning.
Automated transaction monitoring isn't a one-time implementation. It requires ongoing model governance, drift monitoring, and periodic retraining as fraud patterns shift. Build that operational discipline into your plan before you commit to a platform.
- AI fraud detection uses machine learning models, neural networks, and behavioral analytics to identify suspicious transactions and account activity in real time.
- Rule-based fraud detection applies a predefined set of logic to every transaction.
- The gap between rule based vs AI fraud detection isn't about speed or technology alone.
- False positives are the hidden tax of fraud detection.
- Real-time fraud detection means scoring a transaction and making an allow-or-block decision in under 300 milliseconds, before the payment clears.
Onboard Customers in Seconds
Conclusion
The rule based vs AI fraud detection comparison doesn't produce a universal winner. Rule-based systems offer auditability, rapid deployment, and clear regulatory narratives. AI systems offer adaptability, lower false positive rates, and detection of fraud patterns no human thought to write a rule for. The data consistently shows AI reducing false positive volumes by 50-80% and improving detection of novel fraud, but that advantage depends on data quality, model governance, and implementation discipline.
For most banks, fintechs, and insurers today, the right answer is a hybrid: rules for compliance certainty, AI for adaptive detection, and analysts focused on genuine ambiguity rather than clearing false alarms. Start by auditing your current false positive rate and alert-to-confirmed-fraud conversion ratio. Those two numbers will tell you exactly where your system is failing and how much a better-tuned approach could realistically save.
Ready to see what a modern fraud detection stack looks like for your organization? Start with an honest assessment of what your current detection gaps actually cost.



Share this article