.webp)




Introduction
Graph neural networks fraud detection is rewriting how financial institutions catch sophisticated fraudsters, and the change is not incremental. Banks and fintechs that still rely on rule-based thresholds are increasingly blind to the coordinated, network-level attacks that define today's fraud environment. This post explains how GNNs work, why they outperform legacy models, and what your security and compliance teams need to know before evaluating them for production.
- What Are Graph Neural Networks and Why Do They Matter for Fraud Detection?
- How GNNs Expose Fraud Rings Legacy Systems Miss
- Synthetic Identity Fraud and Deepfake Detection in Banking
- Identity Verification Fintech: Where GNNs Fit In
- How Graph Neural Networks Fraud Detection Compares to Rule-Based Systems
Onboard Customers in Seconds
What Are Graph Neural Networks and Why Do They Matter for Fraud Detection?
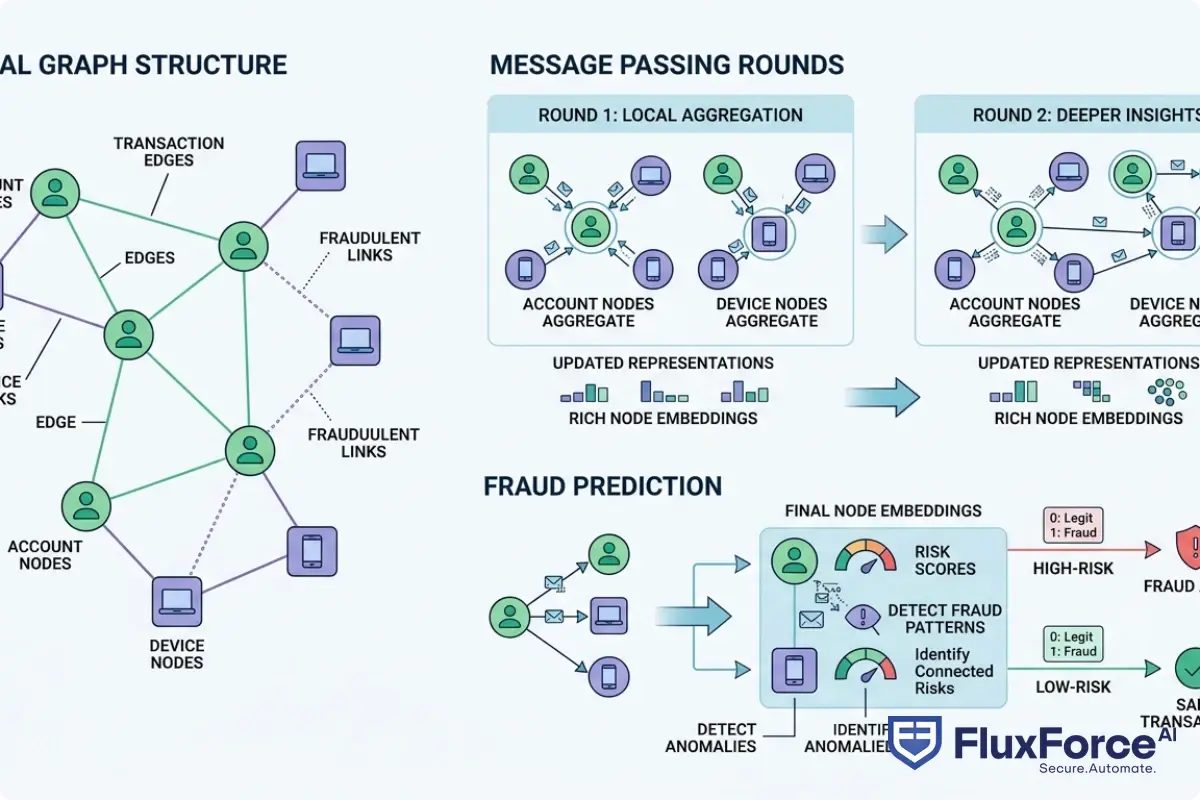
Graph neural networks are a class of machine learning models designed to learn from data structured as graphs: nodes (entities like accounts, devices, or IP addresses) connected by edges (relationships like transactions, shared credentials, or login events).
Traditional fraud detection treats each transaction in isolation. A GNN treats it as a node in a web of relationships. That distinction is not minor. A single account applying for a new credit line may look completely legitimate. But if that account shares a phone number with six other accounts that defaulted last quarter, a GNN catches it; a rule engine probably does not.
How GNNs Model Entity Relationships
At the core, a GNN passes messages between neighboring nodes and aggregates those messages to update each node's feature representation. After several rounds of message passing, each node's embedding reflects not just its own attributes but the behavior of its entire local neighborhood.
For fraud detection, this means:
- An account node accumulates signals from every device it has logged in from
- A device node accumulates signals from every account that used it
- A transaction node reflects patterns across both the sending and receiving accounts
The result is a feature vector rich enough to distinguish a genuine new customer from a synthetic identity that happens to be presenting clean, individual-level data.
Why Traditional Fraud Detection Misses Connected Signals
Rule-based systems check conditions. Gradient boosting models score individual transactions. Neither approach was built to traverse graphs. When a fraud ring creates 200 synthetic identities using permutations of the same stolen personal data, each individual identity may score under every threshold. The GNN sees the structure; the legacy model sees 200 clean accounts.
How GNNs Expose Fraud Rings Legacy Systems Miss
Fraud rings are the real target here. Organized groups build layered networks: mules at the edges, synthetic identities as buffers, and orchestrators at the center. They specifically design their operations to stay below individual detection thresholds.
GNNs do not need to catch each node individually. They score the graph structure itself. An account with no suspicious history still scores high-risk if it sits two hops from five flagged accounts with overlapping device fingerprints.
Synthetic Identity Fraud Detection at Scale
Synthetic identity fraud is the fastest-growing category of financial fraud in the United States, accounting for an estimated $20 billion in annual losses, according to NIST guidance on digital identity management. It combines real and fabricated personal data to build clean identities over months before the fraudster cashes out.
Synthetic identity fraud is the fastest-growing category of financial fraud in the United States, accounting for an estimated $20 billion in annual losses, according to NIST guidance on digital identity management.
GNNs are particularly effective at synthetic identity fraud detection because synthetic identities almost always share infrastructure. They get created in batches using the same device, the same email domains, the same IP ranges. Those shared edges are invisible to score-based models and obvious to graph traversal.
The earlier you catch synthetic identity clusters, the less damage they do. Detecting synthetic identity fraud in real-time at the onboarding stage, rather than after credit drawdown, can prevent millions in losses per fraud ring.
Node and Edge Representation in Financial Networks
What gets represented as a node in a financial GNN depends on the use case:
| Node Type | Examples |
|---|---|
| Account | Bank account, loan application, wallet |
| Device | Mobile device, browser fingerprint, IP address |
| Identity | SSN, email, phone number, address |
| Transaction | Payment, transfer, withdrawal |
Edges represent interactions: account A sending money to account B, device X logging into accounts Y and Z, or one SSN appearing on applications for three separate accounts. The combination of node features and edge types gives the model enough signal to identify fraud rings without needing ground truth labels for every node.

Synthetic Identity Fraud and Deepfake Detection in Banking
The fraud environment in 2025 has two converging problems: synthetic identities built from stolen data, and AI-generated media used to defeat verification checks. GNNs address the first directly and pair with specialized identity verification layers to address the second.
Deepfake Detection Banking and Liveness Detection Fraud
Deepfake detection banking is now a compliance requirement, not just a technical option. Fraud teams at major European banks reported a 400% increase in AI-generated document fraud attempts between 2023 and 2024, according to Europol's financial crime unit. Attackers generate photorealistic ID documents and synthetic face videos to pass identity checks at onboarding.
Liveness detection fraud is the companion threat: adversarial attacks that feed pre-recorded or AI-generated video streams to camera-based verification systems. Effective prevention requires both algorithmic checks (irregular blinking patterns, depth inconsistencies, pixel-level artifacts) and network-level analysis that flags devices involved in prior deepfake attempts across other institutions.
The GNN component adds what no standalone liveness check can: it asks whether the device attempting verification has a history of fraud attempts across the graph, even if the current attempt looks individually clean.
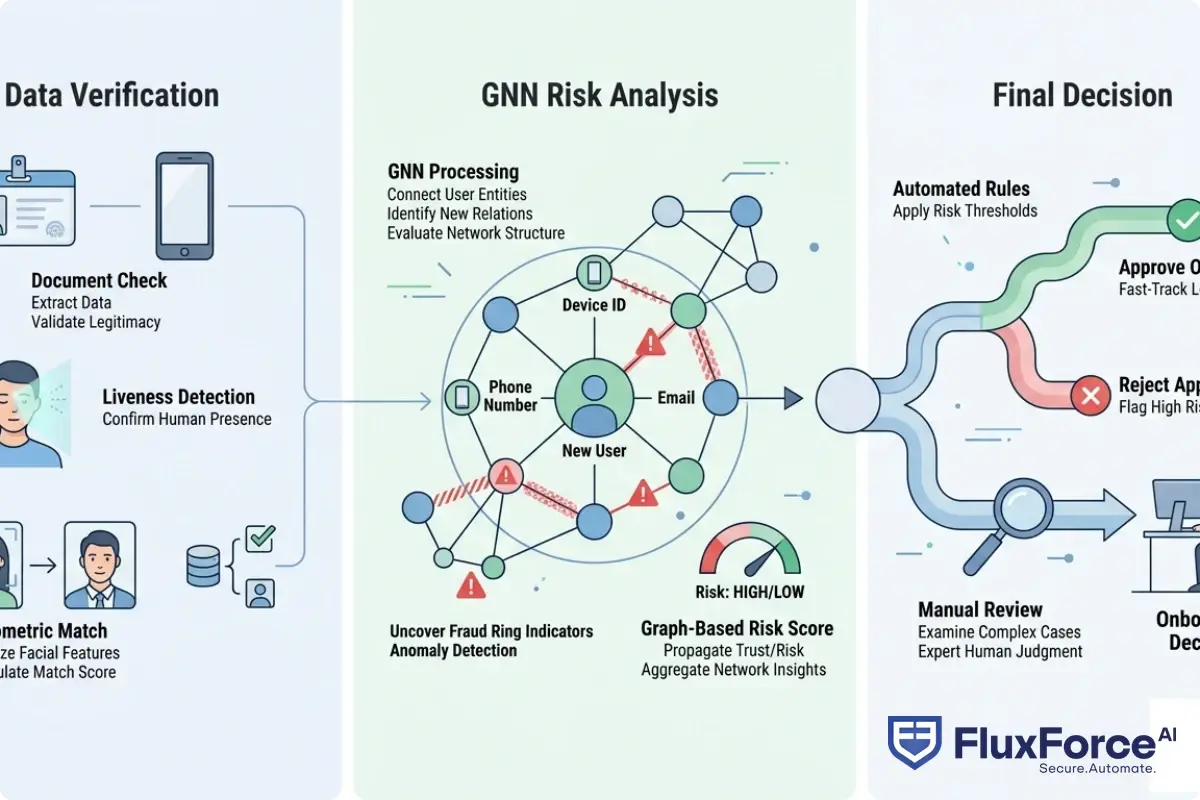
Biometric Identity Verification in Real-Time Onboarding
Biometric identity verification confirms a person's identity using physical or behavioral characteristics: face scans, fingerprints, voice patterns, and increasingly, typing cadence and touchscreen behavior. When integrated into KYC workflows, biometric checks run in seconds and generate a match score.
The honest limitation: biometric match scores are probabilistic. A 98% match is not proof of liveness, and it does not tell you whether the same biometric profile was submitted for 12 other accounts last week. That relationship context comes from the graph layer.
A 98% match is not proof of liveness, and it does not tell you whether the same biometric profile was submitted for 12 other accounts last week.
GNNs consume biometric verification outcomes as node features, then enrich them with relationship data. This catches re-use of synthetic biometric profiles across multiple accounts and flags patterns that a standalone biometric check will never surface.
Identity Verification Fintech: Where GNNs Fit In
Identity verification fintech describes the stack of tools and services that financial institutions use to confirm who they are dealing with, both at onboarding and throughout the customer lifecycle. It includes document verification, biometric checks, sanctions screening, database lookups, and graph-based risk scoring.
GNNs are not a replacement for the rest of that stack. They sit above it, consuming signals from each layer as node and edge features, and outputting a unified risk score that accounts for both individual attributes and network context.
Digital Identity Proofing and KYC Onboarding Speed
Digital identity proofing is the process of remotely confirming that an applicant is who they claim to be, without an in-person interaction. Banks and fintechs face a real tension here: thorough proofing improves fraud detection, but slower proofing increases application abandonment.
KYC onboarding speed is a genuine competitive metric. Fintechs built early growth partly on fast account opening, while traditional banks still rely on multi-day manual processes. The pressure to accelerate KYC without sacrificing quality is exactly why GNN-based risk scoring is attractive: it flags high-risk applications for manual review and fast-tracks low-risk ones, improving both security and conversion.
A well-tuned GNN reduces manual review rates by 30-40% because it has better signal on which applications actually need a human decision. That directly improves KYC onboarding speed without loosening fraud controls.
Identity Verification API: Connecting GNNs to Existing Stacks
An identity verification API exposes risk scoring, document verification, and biometric matching as programmatic endpoints that developers integrate into product flows. GNN inference runs as a microservice that takes an account or transaction as input and returns a risk score along with the contributing graph factors.
For enterprises running existing identity verification API infrastructure, adding a GNN layer typically involves:
- Streaming transaction and event data into a graph database (Neo4j and Amazon Neptune are common choices)
- Running periodic or real-time GNN inference on updated subgraphs
- Returning enriched risk scores to downstream decisioning systems
The integration does not require replacing existing stacks. Most banks add GNN scoring as an additional feature input to existing decision engines rather than as a full replacement.
How Graph Neural Networks Fraud Detection Compares to Rule-Based Systems
The comparison that matters most for CISOs and compliance officers is not benchmark accuracy. It is operational impact: how many fraud cases does each approach catch, how many false positives does it generate, and how much analyst time does it consume.
False Positive Rates: A Side-by-Side View
Rule-based systems generate high false positive rates because rules cannot adapt to new fraud patterns without manual updates. A threshold that flags all transactions over $5,000 catches some fraud and flags a lot of legitimate activity. Analysts spend most of their time clearing cases that were never suspicious.
A threshold that flags all transactions over $5,000 catches some fraud and flags a lot of legitimate activity.
GNNs trained on graph-structured data typically reduce false positives by 40-60% compared to rule-based approaches on the same fraud categories. Agentic AI fraud systems have demonstrated false positive reductions up to 80%, which translates directly to analyst capacity freed for genuine investigations.
GNNs are not immune to false positives. They inherit biases from training data and can over-flag accounts that share infrastructure with fraudsters without being fraudsters themselves. The difference is that GNN false positives tend to cluster around genuinely ambiguous cases, not large volumes of clearly clean transactions.
Graph Models vs. Gradient Boosting for Fraud
For teams coming from gradient boosting models (XGBoost, LightGBM), the transition to GNNs involves a genuine increase in complexity. Gradient boosting is simpler to train, easier to explain, and faster to iterate on. If your fraud problem is primarily transactional and fraud rings are not sophisticated enough to deliberately stay below individual thresholds, gradient boosting may still be the right tool.
GNNs add the most value when fraud rings are deliberately distributed across accounts to avoid individual-level detection, synthetic identity fraud is the primary threat, or you have rich relationship data that gradient boosting cannot efficiently use. For a detailed comparison of AI versus traditional fraud detection approaches, including where rule-based systems still have a role, the decision is more nuanced than most vendor presentations suggest.
Zero Trust Financial Services and GNN-Powered Architecture
Zero trust financial services architecture operates on the principle that no user, device, or transaction should be trusted by default. Every access request gets evaluated continuously against current risk signals, regardless of whether it originates inside or outside the network perimeter.
GNNs fit naturally into a zero trust model because they produce continuous risk scores rather than binary allow/deny decisions. An account that was low-risk last week can be re-scored after its device appears in a new fraud cluster, triggering step-up authentication without manual intervention.
Zero Trust Security Framework and Continuous Verification
The zero trust security framework in banking has three verification layers that GNNs directly improve:
- Identity verification at access: Confirming the person is who they claim to be using biometric identity verification, document checks, and liveness detection
- Device trust assessment: Scoring the device based on its network history and graph relationships
- Behavioral monitoring: Detecting deviations from established patterns during the active session
GNNs operate across all three layers by maintaining a live graph of relationships between users, devices, and behaviors. When any node gets flagged, neighboring nodes are re-scored immediately. For teams building out zero trust security architecture for banking operations, GNN-based continuous scoring replaces the static risk tiers that most legacy implementations rely on.
Zero Trust Financial Services in Practice
Implementing zero trust in a large bank is not a single project. Most institutions take 18-24 months to move from a perimeter-based model to continuous verification. GNNs typically enter in the fraud detection layer first, because the business case is clear and the graph data (transaction history, device logs) already exists in most institutions.
The zero trust security framework then expands: device risk scores feed into session management, identity risk scores feed into authentication policy, and network-level graph signals feed into API gateway controls and anomaly detection. Each layer benefits from the graph's accumulated relationship knowledge.
Deploying Graph Neural Networks Fraud Detection in Production
There is a meaningful gap between a GNN proof of concept and a GNN running in production at a regulated financial institution. The technical challenges are real, and so are the compliance requirements.
Data Requirements and Model Training for Financial GNNs
The single biggest barrier to GNN adoption is data. GNNs need historical transaction data going back at least 12-24 months, device and behavioral event logs linked to account identifiers, confirmed fraud labels rather than just flagged cases, and graph construction logic that maps entities and relationships correctly.
Data quality matters more than data volume. A GNN trained on poorly linked data, where the same customer appears as five different nodes because of ID inconsistencies, learns the wrong patterns. Data preparation typically takes 40-60% of total implementation time.
Integration Timelines and Team Requirements
A realistic enterprise GNN deployment timeline:
| Phase | Duration | Key Activities |
|---|---|---|
| Data audit and prep | 6-8 weeks | Entity resolution, graph schema design, label validation |
| Model development | 8-12 weeks | Architecture selection, training, offline evaluation |
| Staging integration | 4-6 weeks | API development, shadow mode testing, threshold calibration |
| Production rollout | 4-8 weeks | Phased traffic routing, monitoring setup, analyst training |
The team needs data engineers with graph database expertise, ML engineers familiar with PyTorch Geometric or DGL, and fraud and compliance domain experts who can validate outputs against real cases. Regulators expect banks to explain adverse decisions, and GNN explanations are harder to produce than decision tree outputs. Build explainability tooling from the start, not as an afterthought.
- Graph neural networks are a class of machine learning models designed to learn from data structured as graphs: nodes (entities like accounts, devices, or IP addresses) connected by edges (relationships like transactions, shared credentials, or login events).
- Fraud rings are the real target here.
- The fraud environment in 2025 has two converging problems: synthetic identities built from stolen data, and AI-generated media used to defeat verification checks.
- Identity verification fintech describes the stack of tools and services that financial institutions use to confirm who they are dealing with, both at onboarding and throughout the customer lifecycle.
- The comparison that matters most for CISOs and compliance officers is not benchmark accuracy.
Onboard Customers in Seconds
Conclusion
Graph neural networks fraud detection gives financial institutions something rule-based systems and gradient boosting models fundamentally cannot: the ability to score fraud risk based on the structure of relationships, not just individual transaction attributes. For synthetic identity fraud, deepfake detection banking scenarios, and organized fraud rings, that distinction separates early detection from expensive write-offs.
The technology is mature enough for production deployment, but the implementation requires serious investment in data infrastructure, ML engineering, and compliance readiness. Institutions getting the best results started with a focused use case, with synthetic identity fraud detection at onboarding being the most common entry point, proved ROI, then expanded the graph to cover additional fraud categories.
If your team is evaluating graph-based fraud detection alongside your broader AI-powered fraud detection strategy, start with the data audit. The model is the easy part.



Share this article