.webp)



Listen To Our Podcast🎧

Fraud detection API integration is the fastest way for banks, fintechs, and insurers to deploy AI-powered protection without rebuilding core systems from scratch. Most institutions already have transaction pipelines, CRM data, and risk rules in place. The challenge is connecting those systems to modern AI engines that can actually use that data. Done right, the integration takes days, not months, and the payoff is immediate: lower false positive rates, fewer manual reviews, and fraud caught before it hits the settlement layer. This post walks through exactly how to do it, including what to watch out for when choosing transaction monitoring software and how to stop fraud alert fatigue from overwhelming your operations team.
What Is Fraud Detection API Integration (and Why Legacy Systems Fall Short)
Fraud detection API integration means connecting your existing payment, identity, or transaction systems to an external AI fraud detection engine via a standardized interface, typically REST APIs or webhook event streams. The engine scores transactions, flags anomalies, and returns decisions in milliseconds without requiring you to replace your core banking platform.
Legacy rule-based systems work differently. They match transactions against a predefined list of conditions: transaction over $10,000, new device, new country. These rules catch known patterns but miss unknown ones, and every fraudster who has been caught once learns to route around them. The result is a system that is simultaneously over-blocking legitimate customers and under-blocking sophisticated attacks.
Why Legacy Systems Create Compliance Bottlenecks
Static rules create a maintenance problem. Every new fraud typology requires a new rule, a compliance review, and testing, which takes six to eight weeks on average. By the time the rule is live, the typology has evolved. This is why ai fraud detection explained as a concept has gained traction: AI models update continuously based on new transaction data rather than waiting for someone to write a new rule. For a deeper look at how this plays out across different risk profiles, AI vs. Traditional Fraud Detection: Key Differences Every Risk Officer Should Know is a useful starting point.
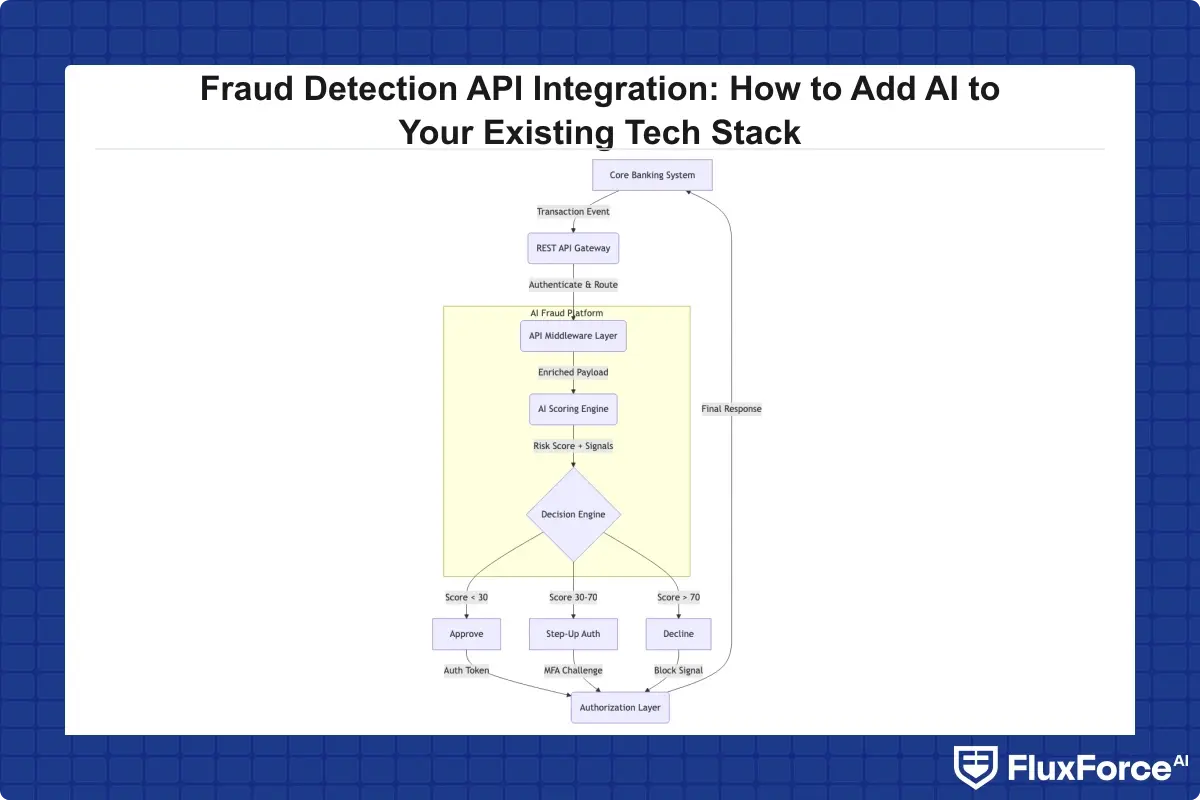
What the Modern Integration Actually Looks Like
A modern fraud detection API integration sits between your authorization layer and your settlement layer. Every transaction event is posted to the API endpoint. The response comes back with a risk score, a recommended action (allow, decline, step-up authentication), and an explanation string that your compliance team can use for audit trails. The entire round trip typically completes in under 100 milliseconds, which means customers see no latency increase during checkout or login.
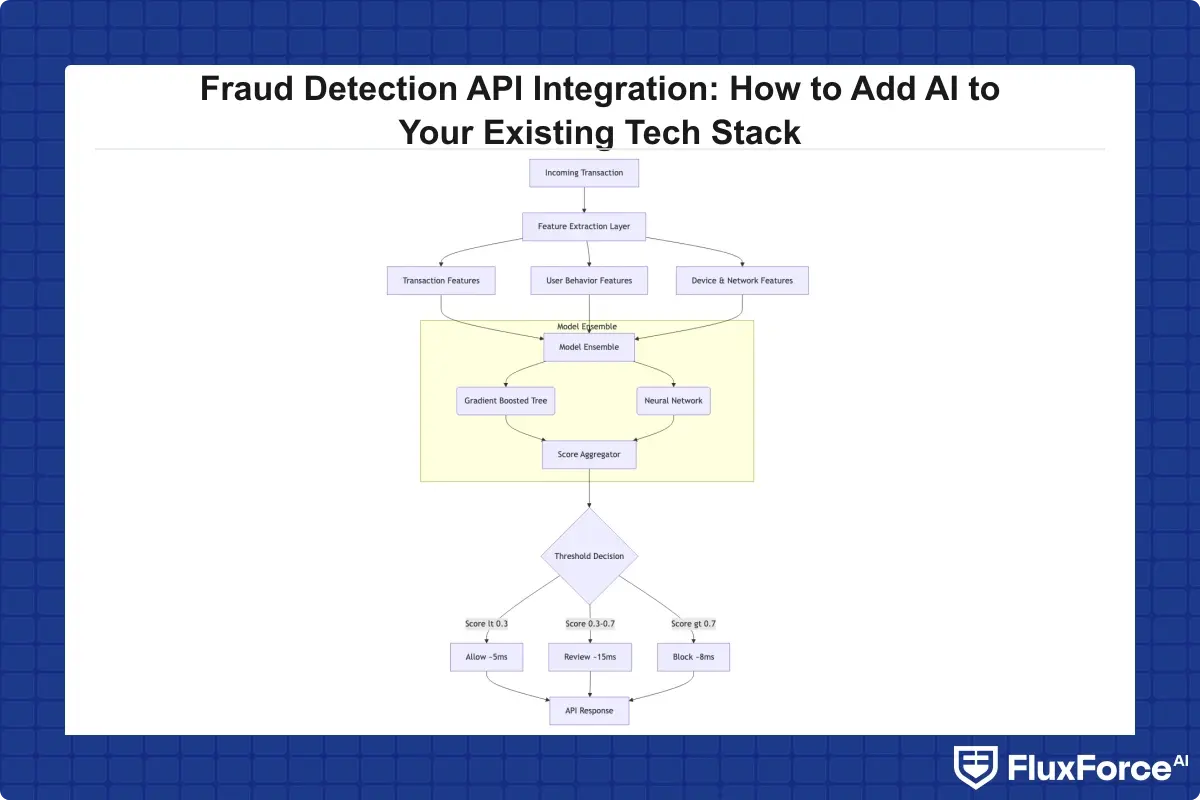
How Does AI Detect Fraud in Real-Time?
AI fraud detection works by training machine learning models on historical transaction data labeled as fraudulent or legitimate. The model learns which combinations of features, including device fingerprint, velocity, behavioral biometrics, merchant category, and location delta, predict fraud. During live transactions, the model applies those learned patterns in milliseconds and returns a probability score.
The clearest answer to how does ai detect fraud is this: it compares each new transaction to millions of historical patterns simultaneously, identifies statistical anomalies, and adjusts its confidence based on contextual signals no static rule can capture.
Behavioral Analytics and Anomaly Detection
Behavioral analytics tracks what normal behavior looks like for each individual user: typing speed, swipe patterns, session duration, and typical transaction amounts. When a transaction deviates significantly from that baseline, it triggers a review. This is especially effective for account takeover fraud, where the credentials are legitimate but the behavior is not.
How Machine Learning Models Score Transactions
Machine learning fraud detection uses ensemble methods in most production systems. A gradient-boosted tree handles high-volume, low-context transactions. A neural network handles behavioral sequences. A rules layer handles regulatory hard stops. All three scores combine into a final risk decision, reducing both the false positive rate and the false negative rate compared to any single model in isolation.
Real-Time Fraud Detection in Banks: Latency Requirements
Real time fraud detection banks typically run is constrained to under 150 milliseconds end-to-end, including network transit. Any longer and the authorization timeout fires before the fraud score returns. Real time fraud detection systems deployed with edge compute or multi-region redundancy eliminate this bottleneck. This is why API hosting region matters when selecting a vendor: a platform hosted in Singapore adds meaningful latency for a European bank processing card authorizations.
The True Cost of Fraud Alert Fatigue
Fraud alert fatigue is what happens when your operations team receives more alerts than they can meaningfully review. Analysts start triaging by volume rather than risk, which means the most dangerous alerts sit in the queue while lower-risk ones get processed first because they are faster to close.
The false positive rate in fraud detection is the real operational driver here. Research cited by FinCEN and independent industry studies indicates that rule-based systems generate false positive rates between 85% and 95% in transaction monitoring. That means for every 100 alerts, fewer than 15 involve actual fraud. The cost of reviewing each alert ranges from $15 to $75 per case depending on complexity.
What High False Positive Rates Actually Cost
False positive cost fraud teams absorb is not just operational. Declining a legitimate transaction costs a bank roughly $5 to $10 in direct losses from refund processing and customer service calls, but the downstream cost from customer churn is four to six times higher. Research from McKinsey Financial Services indicates that banks lose 10% to 12% of customers in the year following a false decline. For a mid-tier bank processing 2 million transactions monthly, the math on lost lifetime value becomes uncomfortable quickly.
How Automated Transaction Monitoring Reduces Alert Volume
Automated transaction monitoring powered by AI cuts alert volume because the model learns which transaction patterns are genuinely risky versus which merely look unusual. A first-time large transaction from a customer who just received a salary deposit is statistically different from the same transaction originating from a dormant account. Rules treat them identically. Machine learning does not.

How Fraud Detection API Integration Works With Your Existing Stack
The practical mechanics of fraud detection API integration depend on where in your architecture you want to insert the fraud signal. Most teams choose one of three insertion points: pre-authorization for the highest impact, post-authorization for catching fraud before settlement, or asynchronous batch for AML screening rather than real-time card fraud.
For most payment fraud prevention use cases involving card transactions, pre-authorization integration is the right choice. The API call happens synchronously during the authorization request, and the result determines whether to approve or decline.
REST API vs. Webhook Event Streams
REST API integration is simpler to implement and works well for request-response patterns like card authorizations. Webhook event streams are better for asynchronous use cases: account changes, login events, or wire transfer initiation. Many modern transaction monitoring software vendors support both patterns. The choice depends on whether your fraud decision needs to block the transaction in real time (REST) or flag it for review after the fact (webhook).
Connecting your stack to an AI-powered fraud detection platform via REST is straightforward if your authorization layer already supports middleware injection. Most modern payment orchestration layers do, and the typical engineering effort is two to five days for a standard integration.
Handling Authentication and Data Privacy in Transit
Every fraud detection API integration must address two security concerns: authentication (is this request from our system?) and data minimization (are we sending only what we need?). OAuth 2.0 bearer tokens handle authentication. For data minimization, most vendors accept hashed identifiers rather than raw PII, which matters considerably under GDPR and PCI DSS. The OWASP API Security Top 10 provides a well-established framework for structuring these controls in regulated environments.
For insurance institutions managing policy payment flows, authentication and data privacy requirements overlap with existing regulatory obligations. Our guide on secure payment gateway strategy for policy underwriting managers covers these compliance intersections in detail.
Testing and Sandboxing Before Production Rollout
Shadow mode is the standard approach: run the fraud detection API in parallel with your existing system for two to four weeks, comparing decisions without acting on them. This gives you a calibration baseline so you can tune thresholds before going live, which significantly reduces the risk of a false decline spike on launch day. Most vendors provide sandbox environments that mirror production traffic volumes, making this phase faster than teams typically expect.
How to Reduce False Positives in Transaction Monitoring
Reducing false positives in fraud detection is not about lowering the sensitivity of your models. It is about making the model smarter about context. A transaction that triggers a velocity rule might be entirely legitimate if it is a corporate payroll run. An AI model trained on your own transaction history learns that distinction. A generic static rule does not.
Adaptive Thresholds vs. Static Rules
The biggest lever for reducing false positives transaction monitoring teams have is switching from static risk thresholds to adaptive ones. Static rules set a fixed limit: flag any transaction over $5,000 from a new IP address. Adaptive thresholds set limits relative to each customer's own history. For a business account that regularly processes $50,000 wire transfers, a $5,000 transaction is unremarkable.
Our analysis on how agentic AI fraud agents cut false positives shows that adaptive threshold systems reduce false positive rates by 60% to 80% compared to static rule sets, without any corresponding increase in missed fraud.
How to Reduce False Positives in AML
How to reduce false positives in AML is a different question from card fraud. AML false positives come from rules designed to catch structuring, layering, and integration of funds. The problem is that many legitimate customers, including small business owners, frequent international travelers, and property investors, have transaction patterns that superficially resemble these typologies.
AI models trained on SAR (Suspicious Activity Report) outcomes rather than just transaction features learn the difference between surface-level similarity and genuine risk. The false positive rate fraud detection teams see in AML contexts typically drops from above 90% to below 30% after deploying properly trained machine learning models. For insurance compliance teams applying similar principles during policy issuance, the KYC/AML identity verification strategy for compliance officers in insurance walks through how to adapt this approach.
Sardine vs Unit21: Comparing Fraud Detection API Integration Options
When evaluating sardine vs unit21, the decision usually comes down to use case specificity versus platform breadth. Sardine focuses heavily on behavioral biometrics and device intelligence, making it strong for onboarding and account creation fraud. Unit21 is a broader case management platform with workflow orchestration, which suits compliance teams that need audit trails and SAR filing support built in.
Transaction monitoring cost varies significantly by vendor and volume tier. Sardine pricing is typically usage-based on events processed. Unit21 charges per alert handled, which aligns cost with operational overhead rather than raw transaction volume. Both platforms offer fraud detection API integration via REST into existing stacks in days, not months.
Choosing Based on Your Fraud Profile
If synthetic identity fraud is your primary exposure, Sardine's device graph and behavioral stack is notably strong for that pattern. If your operations team is overwhelmed by alert volume and needs better case management workflow, Unit21 addresses a different operational problem. Neither platform is universally better. The right choice depends on where your fraud losses are concentrated and what your operations team does with alerts once they fire.
For a framework to evaluate ai fraud detection software against your specific threat model, start with the fraud typologies driving your highest losses and work backward to the detection capabilities you actually need.
Transaction Monitoring Cost Over Time
Transaction monitoring cost is not just the vendor license. It includes alert review time, integration engineering hours, and the fraud that slips through because analysts are overwhelmed by volume. A cheaper platform with a 90% false positive rate costs more in analyst hours than a more expensive platform with a 20% false positive rate, especially at scale. The right metric is total cost per true positive detected, not monthly subscription fee.
Synthetic Identity Fraud and the Limits of Rule-Based Detection
Synthetic identity fraud is the fastest-growing fraud category in financial services. Rather than stealing a real person's identity, fraudsters build a new identity by combining real data, often a legitimate Social Security Number belonging to a child or elderly person with no credit history, with fabricated supporting information. The constructed identity passes most KYC checks because part of it is genuinely real.
Rule-based payment fraud prevention systems cannot catch this reliably. There is no stolen card signal, no mismatched name. The synthetic account builds credit history over months, behaves normally, and then executes a bust-out event by maxing out all available credit before the account disappears.
How AI-Based Detection Works for Synthetic Identities
AI fraud detection in banking catches synthetic identities by examining relationship networks rather than individual account signals. If a single device, phone number, or email address appears across multiple supposedly distinct customer identities, that is a graph-level pattern no individual account rule can see. Machine learning models that incorporate graph features flag these synthetic identity clusters before the bust-out event occurs.
For a technical breakdown of how this detection works in production environments, Detecting Synthetic Identity Fraud in Real-Time covers the specific model architectures and data signals most effective for this fraud type.
Why Payment Fraud Prevention Requires a Multi-Layer Approach
No single model stops every fraud type. Synthetic identity fraud requires graph analytics. Account takeover requires behavioral biometrics. Card-not-present fraud requires device and velocity signals. Effective payment fraud prevention layers these capabilities together, which is exactly what modern fraud detection API integration platforms are designed to do. The APIs abstract that complexity away from your engineering team so your risk team gets the full protection stack without building it from scratch.
Onboard Customers in Seconds
Conclusion
Fraud detection API integration is not a six-month infrastructure project. For most institutions, a well-scoped integration connecting your authorization or onboarding layer to an AI fraud scoring engine can be running in production within two to four weeks. The harder challenge is operational: getting compliance, engineering, and risk teams aligned on thresholds, escalation paths, and success metrics before you go live.
The core principle is straightforward: ai fraud detection works best when it replaces static rules with adaptive models trained on your own transaction history, integrated at the right point in your payment or onboarding flow. Start with shadow mode, measure your baseline false positive rate, and use that data to calibrate before switching to active enforcement.
If your team is losing ground to fraud alert fatigue, if transaction monitoring cost is climbing without proportional improvement in detection quality, or if synthetic identity fraud is appearing in your portfolio without clear detection signals, the answer is not more rules. It is smarter AI integrated at the right point in your stack. The technology is available today as a REST API call, and the integration is more straightforward than most risk teams expect.



Share this article