.webp)




Introduction
NLP compliance regulatory monitoring is changing how financial institutions handle the one job that never ends: keeping pace with regulatory change. Between evolving FATF guidance, shifting AML thresholds, and constant state-level rulemaking, compliance teams have been swimming in text for years. A single tier-one bank may track over 300 regulatory sources simultaneously, and manual review cannot scale to that volume without sacrificing accuracy. This post breaks down how NLP is deployed across regulatory monitoring and identity verification fintech workflows, and what the implementation actually looks like for CISOs, compliance officers, and developers building these systems.
- How NLP Compliance Regulatory Monitoring Works
- Identity Verification Fintech: The KYC Foundation
- Biometric Identity Verification and Liveness Detection Fraud
- How NLP Compliance Tools Improve KYC Onboarding Speed?
- Synthetic Identity Fraud Detection: The NLP Advantage
Onboard Customers in Seconds
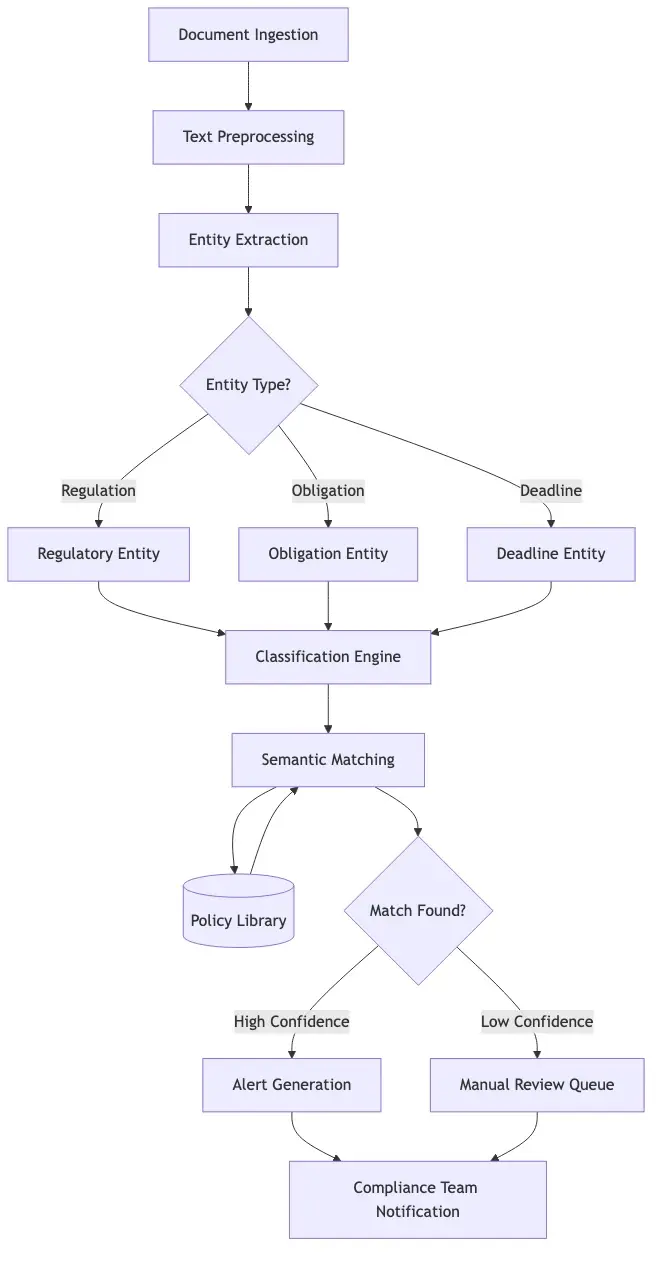
How NLP Compliance Regulatory Monitoring Works
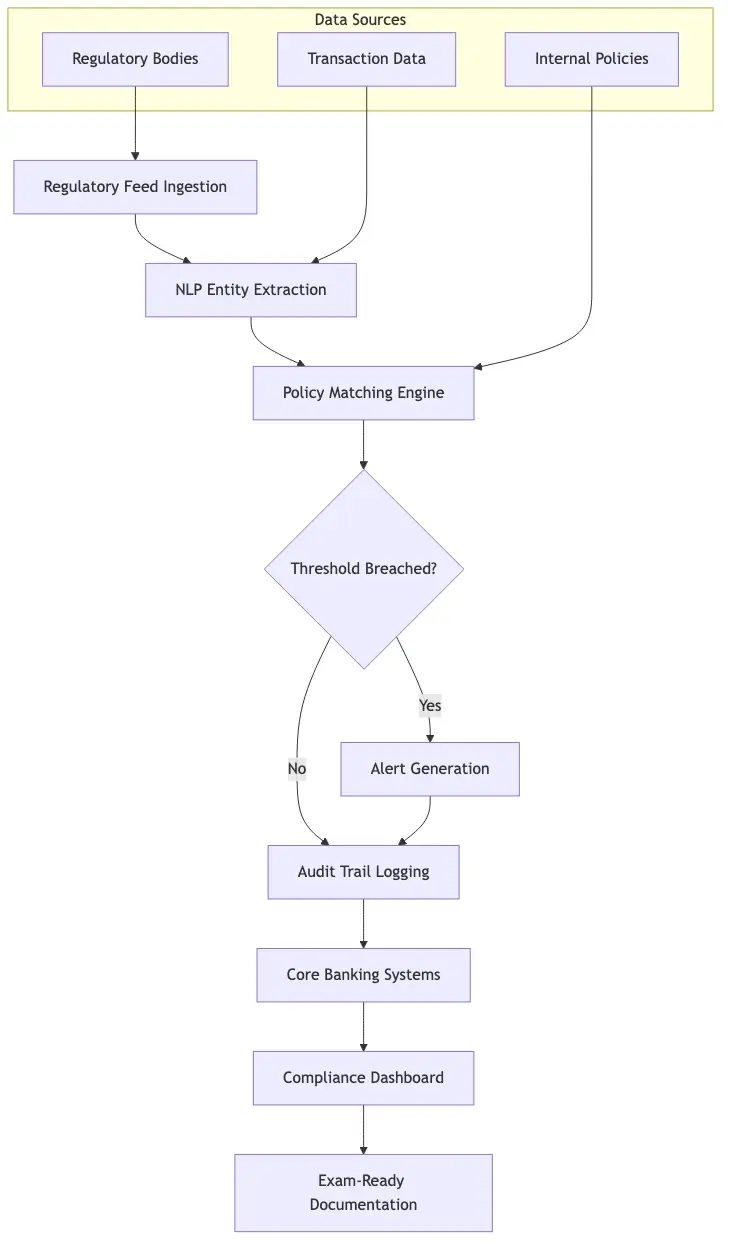
NLP compliance regulatory monitoring starts with a fundamentally boring task: reading regulatory text and deciding whether it changes anything your institution does. Regulators publish thousands of pages annually. NLP changes the economics of that reading.
Processing Regulatory Text at Scale
Modern NLP pipelines ingest regulatory documents (Federal Register notices, prudential guidance, FATF recommendations, PCI DSS updates) and apply named entity recognition, sentence classification, and cross-reference mapping. Instead of an analyst reading a 200-page guidance document, the NLP system surfaces the sentences that require action and flags those that potentially conflict with current policy. According to NIST's AI Risk Management Framework, structured extraction from unstructured regulatory text is one of the highest-value NLP applications in high-stakes domains. Entity extraction also matters because regulations reference each other constantly: an update to one rule may cascade obligations across three others.
Semantic Similarity for Policy Matching
Semantic similarity models compare new regulatory text against your existing policy library. The core question: does this new guidance require updates to written policies? Cosine similarity between sentence embeddings gives compliance teams a ranked list of potentially affected policies within seconds of a new document arriving. That response speed is what makes this operationally viable rather than just technically interesting.
Identity Verification Fintech: The KYC Foundation
Identity verification fintech is the infrastructure layer under most NLP-driven compliance workflows. Before monitoring regulatory compliance in ongoing transactions, you need to confirm who you are dealing with, and that is where KYC onboarding begins.
Digital identity proofing is the process of confirming that a person presenting an identity document is actually who they claim to be, without a human reviewer for every submission. The Financial Crimes Enforcement Network (FinCEN) sets the regulatory baseline for Customer Identification Program requirements in the US. Identity verification fintech infrastructure must satisfy these requirements while supporting a consumer-grade onboarding experience, a tension NLP helps resolve by reducing manual review volume without compromising accuracy.
What Makes Digital Identity Proofing Different
Digital identity proofing relies on OCR to parse document fields, NLP to validate extracted values against expected formats and consistency checks, and machine learning classifiers to flag potentially fraudulent documents. The accuracy of the NLP layer directly determines how much human fallback review remains necessary. When compliance teams integrate KYC/AML automation into their onboarding stack, the biggest gains appear in document extraction and classification, reducing manual data entry and first-pass review while materially improving KYC onboarding speed without adding headcount.
How Identity Verification APIs Connect the Workflow
An identity verification API sits between the customer-facing application and the verification engine. It accepts document images or biometric data, routes them to the processing pipeline, and returns a structured decision with a confidence score. Key evaluation criteria: latency (sub-3-second response is now the consumer standard), explainability (compliance teams need to know why a document was flagged), and false positive rate (excessive manual reviews destroy onboarding economics faster than any other single variable).
Biometric Identity Verification and Liveness Detection Fraud
Biometric identity verification adds a second check beyond document validity: is the person presenting the document physically present, and do they match the photo on file? This is where biometric identity verification and liveness detection intersect in practice.
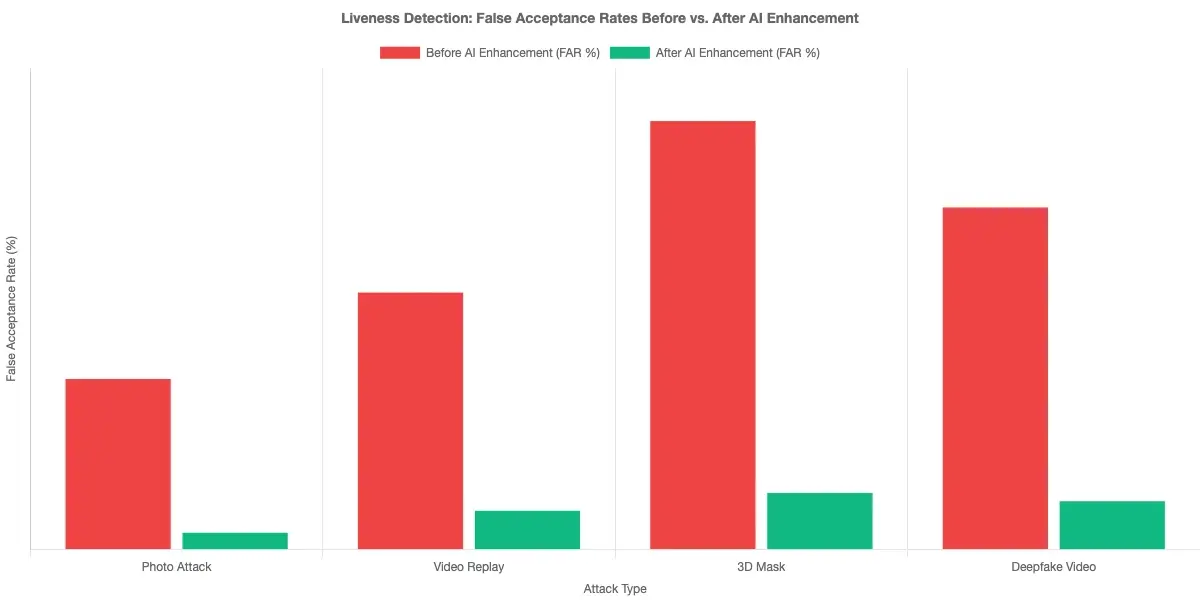
How Liveness Detection Fraud Prevention Works
Liveness detection distinguishes a live person from a photograph, video replay, or 3D mask. Active liveness asks users to perform an action such as blinking. Passive liveness analyzes a single frame for texture and depth cues without user interaction. Passive approaches have better conversion rates but require more sophisticated models to maintain accuracy against evolving attacks. Liveness detection fraud attempts have grown significantly as fraud rings now use high-resolution print attacks and pre-recorded loops designed specifically to defeat older systems. Continuous model retraining is the only effective countermeasure.
Deepfake Detection in Banking: The New Threat Layer
Deepfake detection in banking has moved from theoretical concern to operational priority. Synthetic face generation tools are now accessible enough for fraud rings to use at scale for remote account opening. The multi-layered detection approach combines frequency-domain analysis to catch GAN artifacts invisible to the naked eye, behavioral biometrics to flag unnatural micro-movements, and temporal consistency checks for frame-level anomalies. For a broader look at how this fits into fraud detection architecture, see AI-powered fraud detection strategy for risk teams.
How NLP Compliance Tools Improve KYC Onboarding Speed?
KYC onboarding speed is one of the most concrete metrics identity verification fintech investments get measured against. What was acceptable at 3-5 minutes for digital onboarding is now a conversion problem. Leading institutions hit sub-90-second completion times for fully automated flows.
NLP contributes in three specific ways. First, automated document field extraction eliminates manual data entry: the NLP pipeline extracts name, date of birth, and document number from a driver's license in under 500 milliseconds. Second, edge case classification routes ambiguous submissions to the right review queue immediately rather than piling up for manual triage. Third, adverse media screening runs in parallel with document verification, scanning sources for negative mentions tied to the applicant's name.
Automated Document Review Across Document Types
Document variety is the real challenge. A global institution may process passports, national IDs, and driver's licenses from 180+ countries, each with different layouts, security features, and field structures. NLP systems trained on broad multilingual corpora generalize far better than rule-based OCR systems tied to specific templates, requiring significantly less manual configuration for each new document type.
Reducing Manual Review Volume
Reducing false positives is where NLP pays for itself most clearly. A system flagging 15% of legitimate applications for manual review creates compounding costs: reviewer capacity, applicant drop-off, and reviewer error rate all interact. Institutions replacing rule-based KYC flags with trained classifiers typically see a 40-60% reduction in manual review volume within six months. For the full speed-versus-rigor tradeoff, see manual compliance vs. AI automation.
A system flagging 15% of legitimate applications for manual review creates compounding costs: reviewer capacity, applicant drop-off, and reviewer error rate all interact.
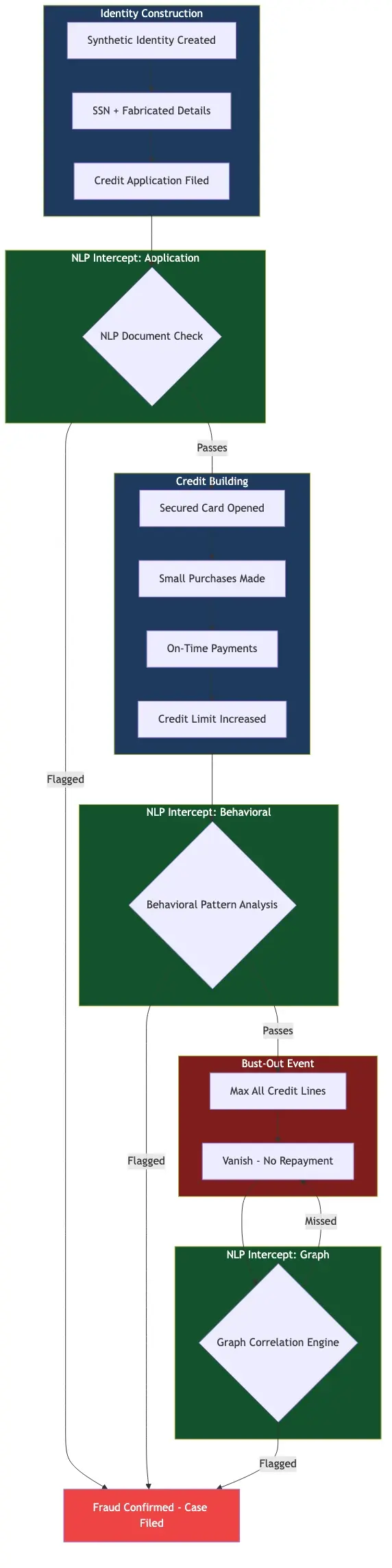
Synthetic Identity Fraud Detection: The NLP Advantage
Synthetic identity fraud detection is one of the harder problems in financial crime. Unlike traditional identity theft, where real credentials are stolen, synthetic identity fraud combines real and fabricated information to construct a fictitious identity cultivated over months before use. NLP's role sits in the behavioral and linguistic layer: patterns in how applications are completed (field order, response timing, linguistic inconsistencies across fields) can signal synthetic identities that pass document and biometric checks. NLP models also test whether employment history descriptions use language consistent with the claimed industry.
Synthetic Identity Fraud Detection in Practice
No single signal is definitive. These accounts are designed to pass individual checks. Detection requires correlating weak signals across multiple data points: document authenticity, biometric match, device fingerprint, behavioral patterns, and application language. Graph-based approaches mapping relationships across synthetic identities (shared phone numbers, overlapping addresses) prove effective when combined with NLP application analysis. See detecting synthetic identity fraud in real-time for the full technical breakdown.
Zero Trust Financial Services: Layering NLP with Access Controls
Zero trust financial services architecture changes identity verification from a one-time onboarding event to a continuous process. Under a zero trust security framework, identity is validated at every sensitive transaction or access request, not just at account opening. NLP fits at the continuous monitoring layer, analyzing transaction narrative patterns, communication anomalies, and support ticket language shifts. A sudden change in how an account interacts with banking systems can trigger step-up authentication before a fraud event completes rather than after.
Zero Trust Security Framework: The NLP Integration Points
- Authentication enrichment: NLP analysis of session context (device, behavioral patterns, transaction language) as an additional signal beyond static credentials
- Transaction risk scoring: Real-time NLP classification of transaction narratives against the institution's historical fraud patterns
- Regulatory alert routing: Automatic escalation of NLP-flagged anomalies to compliance review queues with structured context
- Audit trail generation: NLP-structured summaries of access events satisfying regulatory examination requirements
For teams implementing this in banking, see zero trust security architecture for banking operations and zero trust security for mobile-first banks.
Continuous Verification in Practice
The hard part of continuous verification is not the technology. It is calibrating false positive tolerance. A zero trust system triggering step-up authentication too aggressively creates friction that users find workarounds for. Calibrating NLP-based behavioral models requires ongoing tuning against real transaction data, and that calibration work is specific to each institution's customer base and product mix.
What NLP Compliance Regulatory Monitoring Looks Like in Practice
Deployment of NLP compliance regulatory monitoring tools varies significantly by institution size and scope. A community bank tracking 12 regulatory sources has a different implementation than a global bank monitoring 500+. The core architecture is consistent, but scale and customization requirements differ considerably.
Time-to-Decision Improvements
Time-to-decision is the headline metric. Institutions replacing manual regulatory review with NLP-assisted monitoring consistently report cutting review cycle times from weeks to days. AML alert triage falls from 2-3 hours of analyst work to 15-20 minutes when NLP pre-classifies alerts and surfaces relevant context alongside them. The CFPB's guidance on AI in financial services sets expectations around explainability and adverse action notices that any NLP-based compliance system must satisfy regardless of implementation model.
Audit Trail Quality
Audit trail quality improves because NLP systems generate structured, searchable records of every compliance decision and the evidence driving it. During regulatory examinations, examiners want to see not just what decisions were made but the reasoning behind them. NLP-structured logs satisfy that requirement in ways that informal analyst notes do not.
What Should You Look for in an NLP Compliance Tool?
Evaluating NLP compliance tools is harder than the marketing makes it look. Every vendor claims accuracy, explainability, and easy integration. Meaningful differentiation is in the operational details.
Integration Flexibility and API Design
The identity verification API architecture matters as much as the NLP models it exposes. Look for a REST API with documented rate limits and SLA guarantees, webhook support for asynchronous alert delivery, SDKs in the languages your team uses, and a sandbox that accurately reflects production data. Teams that have shipped a KYC platform know that vendor integration timelines are optimistic. Honest vendors publish case studies with actual timelines, including the edge cases.
Explainability and Audit Readiness
Regulators are increasingly specific about AI explainability in financial services. An NLP model flagging a KYC application as high-risk must produce a human-readable rationale that satisfies both internal review and potential examiner scrutiny. SHAP-based or LIME-based explanations surfacing the specific text features driving a classification are the current standard for audit-ready NLP systems. For compliance officers managing sanctions screening alongside NLP monitoring, see sanctions screening regulatory compliance automation for the explainability requirements specific to that context.
NLP compliance tools reduce manual review volume but do not replace human judgment. The value is force multiplication: your existing compliance team covers more ground with better context at each decision point.
- NLP compliance regulatory monitoring starts with a fundamentally boring task: reading regulatory text and deciding whether it changes anything your institution does.
- Identity verification fintech is the infrastructure layer under most NLP-driven compliance workflows.
- Biometric identity verification adds a second check beyond document validity: is the person presenting the document physically present, and do they match the photo on file?
- KYC onboarding speed is one of the most concrete metrics identity verification fintech investments get measured against.
- Synthetic identity fraud detection is one of the harder problems in financial crime.
Onboard Customers in Seconds
Conclusion
NLP compliance regulatory monitoring is one of the technology investments in financial services where the ROI is measurable, use cases are concrete, and regulatory pressure continues to grow. Institutions that have moved from manual review to NLP-assisted monitoring report material reductions in analyst workload, faster time-to-decision, and better audit trail quality, results that compound as the regulatory environment grows more complex.
The identity layer (biometric identity verification, liveness detection fraud prevention, synthetic identity fraud detection, and digital identity proofing) connects directly to NLP compliance infrastructure. These are not separate tool categories. They are components of a unified compliance architecture that starts at onboarding, extends through continuous transaction monitoring, and terminates at examination-ready documentation.
If your institution is deciding where to begin, KYC onboarding speed is the most tractable entry point. The ROI is visible within months, the integration path is well-defined, and audit trail improvements are immediately useful. Zero trust financial services integration follows naturally from there. The compliance function does not shrink as regulation expands, but with the right NLP infrastructure, it stays manageable.



Share this article