.webp)




Introduction
Explainable AI finance is no longer a nice-to-have feature for compliance teams - it is quickly becoming a legal requirement. When a model denies a loan, flags a transaction as suspicious, or rejects a customer during digital onboarding, regulators want to know why. The EU AI Act, GDPR Article 22, and the Federal Reserve's SR 11-7 guidance all place accountability on institutions that make automated decisions affecting consumers. Black-box models cannot answer that question, and that silence is expensive. This post breaks down where the compliance risk lives, why identity verification workflows are especially exposed, and what explainable AI implementations actually look like in regulated financial institutions.
- Why Explainable AI Finance Is a Regulatory Requirement, Not a Feature
- What Is Identity Verification Fintech? How AI Transparency Applies
- How Black-Box Models Hurt KYC Onboarding Speed Without Warning
- Biometric Identity Verification and the Explainability Gap
- Liveness Detection Fraud and Deepfake Detection Banking
Onboard Customers in Seconds
Why Explainable AI Finance Is a Regulatory Requirement, Not a Feature
Regulators have spent the past decade catching up to machine learning, and that process is now largely complete. What was once informal guidance is codified law in several jurisdictions, and enforcement actions are following.
The Regulatory Push Behind Model Transparency
The Federal Reserve's SR 11-7 guidance (2011) required banks to validate and document all quantitative models used in decision-making. The EU AI Act (2024) classifies credit scoring, insurance risk assessment, and access-to-financial-services models as high-risk AI systems, requiring documentation, human oversight, and on-demand explanation capability. GDPR Article 22 gives individuals the right to request a meaningful explanation when they are subject to an automated decision that significantly affects them.
These three frameworks together mean that most AI used in consumer-facing financial decisions already carries explainability obligations. The question is not whether you need to comply - it is whether your current model architecture actually allows you to.
What Counts as an "Explanation" Under SR 11-7 and GDPR
An explanation is not the same as documentation. Having a white paper on your model architecture does not satisfy a regulator who wants to know why this specific customer received this specific decision at this specific time.
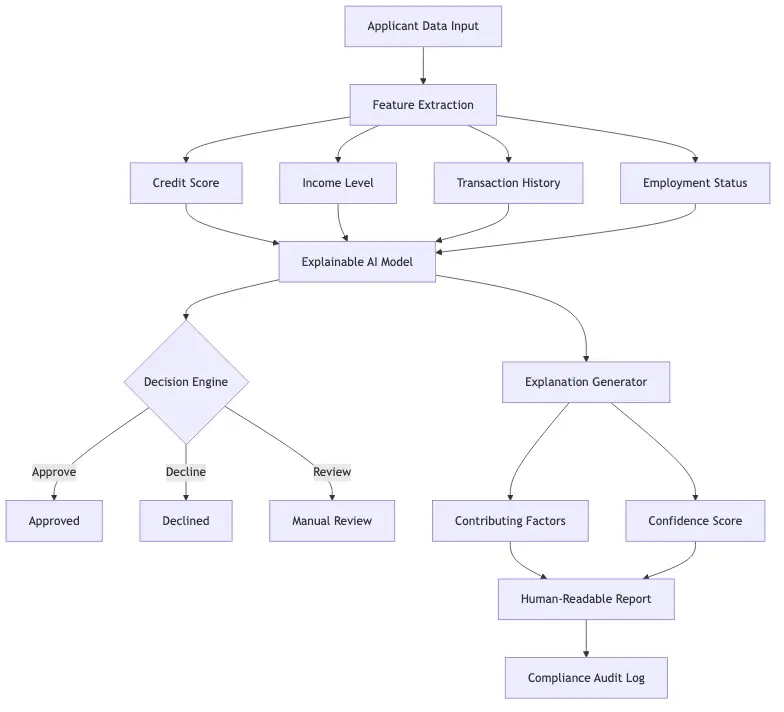
According to NIST's AI Risk Management Framework, a useful explanation includes the key factors that drove a decision, the direction of their influence, and their relative importance. That is the operational standard financial institutions are now measured against: not abstract documentation, but decision-level traceability tied to individual outcomes.
What Is Identity Verification Fintech? How AI Transparency Applies
Identity verification fintech refers to software platforms that use AI, biometrics, and document analysis to confirm that a person is who they claim to be during financial onboarding, account access, or transaction authorization. These platforms make binary decisions, often in milliseconds, with no human in the loop.
When a customer is declined during digital onboarding, they receive a generic message. If that customer challenges the decision, or if a regulator requests the audit trail, the institution needs to produce more than a score. Most identity verification fintech implementations today cannot do this cleanly, and that gap is where enforcement exposure lives.
How AI Decisions in Identity Pipelines Create Audit Gaps
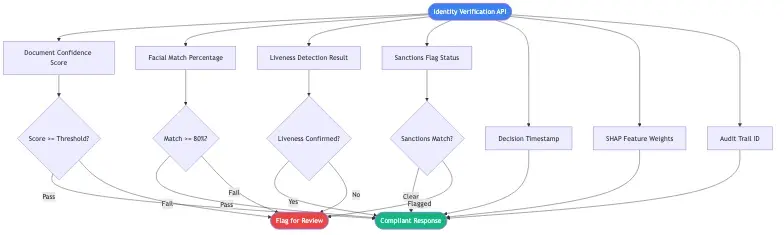
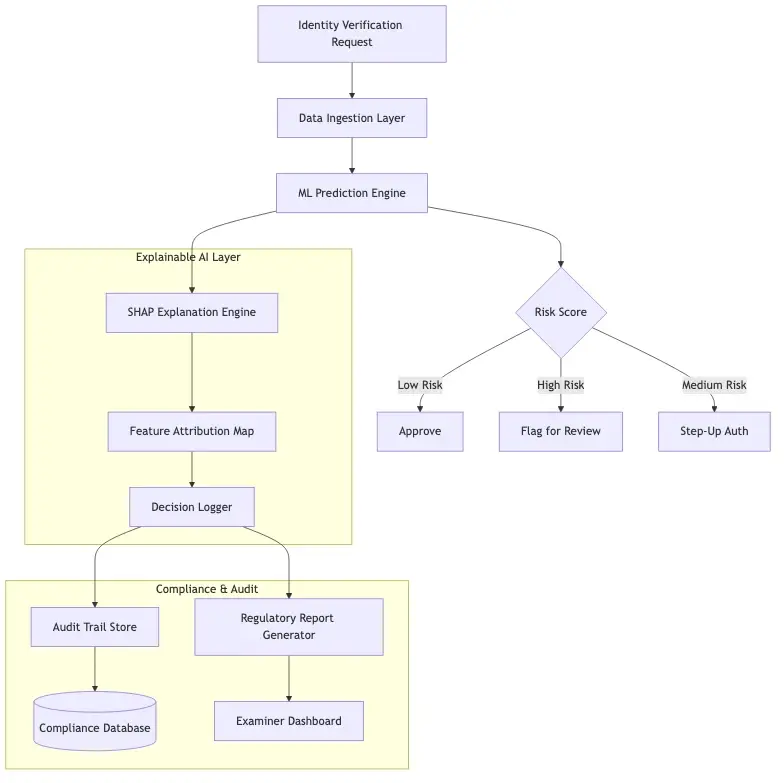
Most identity verification pipelines chain multiple AI models together. A document authenticity model runs first, then a facial match model, then a liveness check, then a sanctions screen. Each model adds its own opaque score to a cumulative result. When the final decision is decline, there is often no clean mapping between the outcome and the specific model or signal that triggered it.
This is where identity verification API integrations create hidden compliance exposure. When institutions consume third-party API responses without capturing the underlying reasoning, they own the decision but lack the explanation. That is not a comfortable position during a regulatory examination.
Why Identity Verification API Outputs Must Be Traceable
A well-designed identity verification API should return not just a pass/fail decision but the sub-signals that contributed to it: document OCR confidence, facial match score, liveness confidence, and any flags triggered during sanctions or PEP screening. Institutions should store these signals alongside every decision record, not just the final outcome.
Regulators look at the trail, not just the endpoint. If an examiner requests the file on a declined customer, the institution should be able to produce the specific signals that drove the outcome within 30 minutes - not 30 days. That is a data architecture requirement, and most institutions have not built to it yet.
How Black-Box Models Hurt KYC Onboarding Speed Without Warning
There is a persistent assumption that explainability and kyc onboarding speed are in tension - that making a model transparent necessarily makes it slower or less accurate. This is not accurate, and the assumption leads institutions to accept opacity they do not need.
The real kyc onboarding speed problem is different. Black-box models that flag borderline cases with no explanation create a manual review bottleneck. Compliance teams have no information to work with, so they escalate everything. Explainable models let reviewers see exactly which signal triggered a flag: an expired document, a facial match confidence of 71% below the 80% threshold, a name on a secondary sanctions list. Reviewers can make informed decisions in minutes rather than hours.
Explainable models let reviewers see exactly which signal triggered a flag: an expired document, a facial match confidence of 71% below the 80% threshold, a name on a secondary sanctions list.
Reducing false positives through explainable AI is one of the most concrete operational benefits institutions see when they move away from opaque models. One UK neobank reported internally that unexplained AI rejections added an average of 3.2 days to customer activation for flagged accounts, because compliance teams had no signal to work from and escalated everything to legal review.
The Accuracy vs. Explainability Trade-Off
The argument that black-box models are meaningfully more accurate is often overstated in a financial services context. Deep learning models can achieve higher raw accuracy on benchmark datasets, but accuracy measured on historical data does not capture regulatory fitness. A model that is 98% accurate but cannot explain its 2% of errors may still fail a supervisory review if those errors cluster around a protected demographic class.
A model that is 98% accurate but cannot explain its 2% of errors may still fail a supervisory review if those errors cluster around a protected demographic class.
Gradient boosting models like XGBoost and LightGBM, combined with SHAP (SHapley Additive exPlanations) values, achieve accuracy within 2-3 percentage points of deep learning models while providing feature-level explanations for every single decision. For most financial use cases, that trade-off strongly favors explainable architectures. The accuracy sacrifice is small; the compliance benefit is large.
Gradient boosting models like XGBoost and LightGBM, combined with SHAP (SHapley Additive exPlanations) values, achieve accuracy within 2-3 percentage points of deep learning models while providing feature-level explanations for every single decision.
When KYC Onboarding Speed Drops Because Compliance Blocks the Model
This happens more often than institutions admit publicly. A fraud or compliance team encounters a model decision they cannot internally justify, escalates to legal, and the entire onboarding queue backs up while the review runs. The problem compounds when the model flags legitimate customers at disproportionate rates for a specific demographic group, triggering a broader audit that can pause operations for days.
Explainability does not just satisfy regulators - it gives compliance teams the confidence to let the model run without constant manual escalation. That operational benefit compounds across thousands of onboarding decisions per day.
Biometric Identity Verification and the Explainability Gap
Biometric identity verification uses physical or behavioral characteristics - facial geometry, fingerprints, voice patterns - to confirm identity. It is the standard approach for digital onboarding across banks, fintechs, and insurers. The accuracy of biometric identity verification has improved significantly over the past five years, but the explainability gap has not closed at the same rate.
Biometric models operate on high-dimensional feature vectors that do not translate naturally into human-readable factors. A facial recognition model does not say the nose bridge geometry is inconsistent with the ID photo. It outputs a similarity score between 0 and 1. When that score falls below a threshold and a real customer is declined, the institution must explain the decision without a clean narrative to reference.
How Biometric Models Score Risk
Most production biometric identity verification systems use one of three output architectures: a single similarity score, a multi-factor confidence breakdown, or a risk-banded classification. The multi-factor breakdown is the most audit-friendly because it separates facial geometry match, texture analysis for spoof detection, and demographic parity checks into distinct reportable signals.
Institutions evaluating biometric vendors should ask directly: what data does your API return when a decision is challenged in a regulatory proceeding? If the answer is only the final score, the vendor's architecture creates compliance exposure for the buyer regardless of the contract terms.
What Happens When a Biometric Decision Gets Challenged
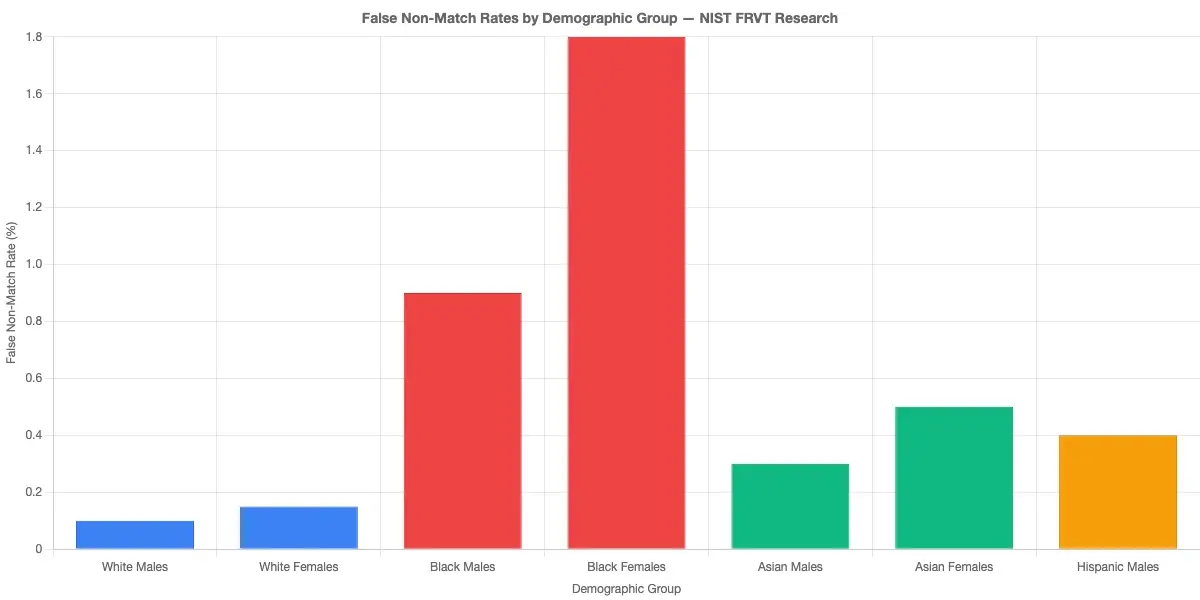
Under GDPR and the UK Equality Act, a customer who believes they were declined due to their ethnicity or appearance has grounds to request a formal review. Biometric models have documented accuracy disparities across demographic groups. NIST's face recognition vendor testing program has measured false non-match rates varying by a factor of up to 100x across demographic groups in some commercial algorithms.
This is not a theoretical concern. It is documented, measurable bias that institutions must be able to audit for in production. Without decision-level explainability, that audit is structurally impossible, and the institution cannot demonstrate whether its biometric system meets demographic parity requirements.
Liveness Detection Fraud and Deepfake Detection Banking
Liveness detection fraud refers to attempts to defeat biometric systems using a photo, pre-recorded video, or fabricated mask instead of a live person. Deepfake detection banking is the countermeasure: AI systems that identify synthetic or manipulated media during the identity verification process.
Both areas create a specific explainable AI finance challenge. When a liveness check fails, the institution needs to know whether the failure was a genuine fraud attempt or a false positive caused by poor lighting, video compression artifacts, or demographic bias in the liveness model itself. Without explanation, there is no way to distinguish between the two.
Why Deepfake Detection Banking Models Are Among the Hardest to Explain
Deepfake detection models identify statistical artifacts in synthetic media: pixel distribution inconsistencies, frame-level facial movement anomalies, and frequency-domain signatures that differ between real and generated faces. These signals are real and detectable, but they are extremely difficult to translate into plain-language explanations for a compliance record.
The approach most institutions are adopting is decision decomposition: rather than trying to explain the deepfake detection model directly, they capture which sub-checks contributed to the flag - frequency analysis, temporal consistency, 3D depth estimation - and log those sub-checks as the structured explanation. This approach aligns with EU AI Act technical documentation requirements for high-risk AI systems and gives compliance teams an auditable signal at every decision point.
Liveness Detection Fraud: Transparency as a Defense Layer
Explainability in liveness detection serves two functions: it satisfies auditors, and it makes the detection system better over time. When compliance teams can see which specific signals triggered a fraud flag, they can identify systematic false positive patterns - for example, a liveness model that consistently declines users with certain camera hardware or specific ambient lighting conditions.
Detecting synthetic identity fraud in real time is closely linked to liveness detection because synthetic identities are often validated using deepfake photos and manipulated documents. Addressing liveness detection opacity simultaneously strengthens the broader synthetic identity fraud detection posture across the onboarding pipeline.
Digital Identity Proofing and Explainable AI Finance Compliance
Digital identity proofing is the process of verifying that a person's claimed identity matches their real-world identity through digital means: document verification, biometric matching, database checks, and behavioral signals. As more financial services move fully digital, digital identity proofing is the first substantive line of defense against account fraud and identity theft.
The compliance challenge is specific: digital identity proofing decisions are high-stakes and individually targeted. They affect particular people's access to financial services, putting them directly in scope for explainability requirements under the EU AI Act, GDPR, and SR 11-7 simultaneously.
Zero Trust Financial Services and Identity Proofing
Zero trust financial services architectures treat every identity verification event as potentially untrustworthy, requiring continuous validation rather than a one-time onboarding check. The zero trust security framework verifies identity at every access point - not just at account creation - which multiplies the number of explainable automated decisions per customer significantly.
Each continuous verification event is technically a separate automated decision with its own compliance exposure. Institutions building zero trust architectures need explainability built into the verification logic at every layer, not added afterward when a regulator asks for the audit trail. This means the explanation infrastructure must be designed into the architecture from the start.
Synthetic Identity Fraud Detection Needs Explainable Signals
Synthetic identity fraud detection depends on explainability more than almost any other AI application in financial services. Synthetic identities pass document checks and pass biometric checks because the person presenting is real - they are simply not who they claim to be. They accumulate realistic credit history over months before being used to access credit lines or commit account takeover.
Effective synthetic identity fraud detection requires AI models that combine dozens of weak signals: address velocity, credit file age, device fingerprint patterns, application timing analysis, and behavioral anomalies. When that composite score triggers a decline, the institution must point to the specific combination of signals that elevated the risk. Without that capability, the compliance team cannot defend the decision and the fraud team cannot improve the model for future cases.
Building Explainable AI Finance Systems That Pass Audits
Explainable AI finance is an architectural discipline, not a single technology selection. The goal is to build systems where explanation is a first-class output produced alongside every decision, not something reconstructed from incomplete logs after a regulator submits a formal inquiry.
The practical implementation requires three components working together: explainable model architectures (SHAP values, LIME, attention mechanisms), decision-level explanation logging at the point of inference, and human-readable reporting tools for regulatory queries. These are all production-ready tools available today. The gap for most institutions is organizational, not technical.
Zero Trust Security Framework Principles That Support Explainability
The zero trust security framework aligns naturally with explainable AI requirements. Zero trust assumes no inherent trust: every access decision must be justified by current evidence. Explainable AI assumes no inherent black box: every model decision must be justified by traceable factors. Both frameworks require logging every decision with its supporting evidence and continuously monitoring for drift and demographic bias.
Institutions that have already adopted zero trust principles find the transition to explainable AI architectures more manageable because the organizational discipline for evidence-based decisions already exists. AML screening workflows benefit directly from this shared audit infrastructure: the explanation data that supports a declined onboarding decision also supports a suspicious activity report filed downstream, reducing duplicate documentation work for compliance teams.
Making Identity Verification API Outputs Auditable
For institutions consuming identity verification APIs from third-party vendors, auditability comes down to two things: contractual requirements and data architecture. The vendor contract should specify the minimum explanation data returned per decision. The institution's data pipeline should capture and store that data alongside every decision record, permanently linked to the customer file.
When an examiner requests the audit trail on a specific declined customer, the institution should be able to produce the decision timestamp, the model version active at that time, the individual signal scores that contributed to the outcome, and the threshold configuration in use. Most institutions today cannot produce this within a reasonable timeframe. Some cannot produce it at all. That is the compliance gap that explainable AI finance architecture closes.
- Regulators have spent the past decade catching up to machine learning, and that process is now largely complete.
- Identity verification fintech refers to software platforms that use AI, biometrics, and document analysis to confirm that a person is who they claim to be during financial onboarding, account access, or transaction authorization.
- There is a persistent assumption that explainability and kyc onboarding speed are in tension - that making a model transparent necessarily makes it slower or less accurate.
- Biometric identity verification uses physical or behavioral characteristics - facial geometry, fingerprints, voice patterns - to confirm identity.
- Liveness detection fraud refers to attempts to defeat biometric systems using a photo, pre-recorded video, or fabricated mask instead of a live person.
Onboard Customers in Seconds
Conclusion
Explainable AI finance bridges the gap between how institutions want to use machine learning and how regulators require them to use it. Black-box models produce accurate outputs but cannot answer the single most important question in a regulated environment: why was this decision made for this person at this time.
Identity verification, KYC onboarding, biometric identity verification, liveness detection fraud, and synthetic identity fraud detection are all areas where that question is asked regularly - by regulators, by customers, and by compliance teams trying to defend decisions in real time. The tools to answer it exist today. SHAP values, interpretable model architectures, and structured explanation logging are all production-ready. The remaining gap is organizational: explainability must become a hard requirement at every AI procurement and deployment decision, not a retrofit applied after a regulatory inquiry lands on your desk.
Start with your highest-volume identity verification decisions. Build the explanation logging infrastructure. Work backward through the rest of your AI stack from there. The cost of not doing this is no longer speculative.



Share this article