.webp)



Listen To Our Podcast🎧

ACH fraud detection prevention is one of the most pressing operational challenges facing financial institutions today. The ACH network processes over 30 billion transactions annually in the United States, according to NACHA's ACH Network statistics, and as volume grows, so does the attack surface for fraudsters targeting corporate and consumer accounts. For banks, fintechs, and payment processors, the question is no longer whether an ACH exploit will be attempted against your rails but how fast your defenses can respond.
This post breaks down the mechanics of ACH fraud, the limits of rule-based systems, and how AI-powered approaches change the speed and accuracy of detection, including the hidden cost of false positives that most compliance teams underestimate.
What Is ACH Fraud and Why Is It Rising?
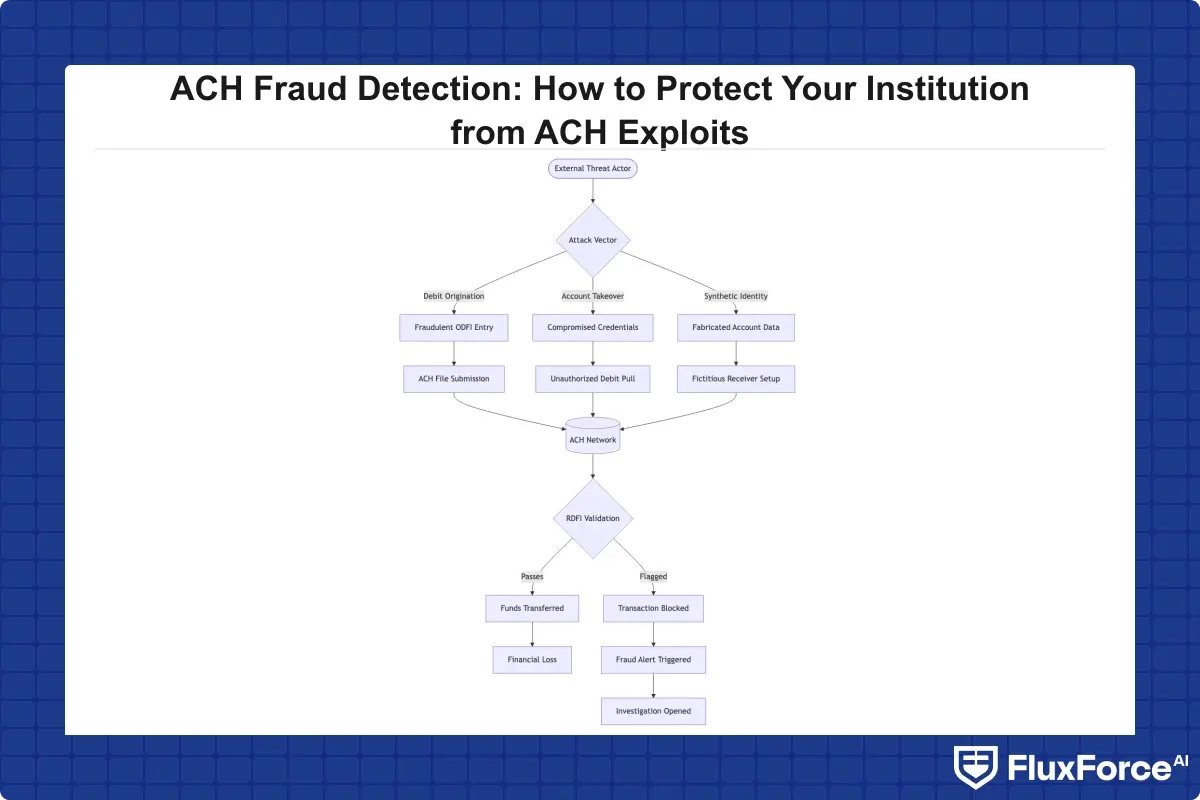
ACH fraud happens when an unauthorized party initiates or manipulates Automated Clearing House transactions to divert funds. It surfaces across several vectors: account takeover, business email compromise, kiting schemes, and unauthorized debit origination. According to the Association for Financial Professionals, ACH debits are the payment type most frequently cited in fraud attempts by corporate treasury teams.
ACH is a batch-settlement network, which means a fraudulent debit authorized at 2 AM may not surface in your monitoring system until the file settles hours later. That delay is what fraudsters exploit.
The Most Common ACH Fraud Schemes
- Account takeover (ATO): Fraudsters obtain banking credentials through phishing or credential stuffing and initiate ACH pulls against victim accounts.
- Corporate account takeover (CATO): Targets business accounts via malware that intercepts ACH batch files before transmission.
- Unauthorized debit origination: An originator submits debits without proper consumer authorization.
- Check kiting: Exploiting the settlement window to create artificial balances across multiple accounts.
- Synthetic identity fraud layered on ACH: Fabricated-identity accounts receive fraudulent ACH credits before detection.
Why Traditional Payment Fraud Prevention Falls Short
Rule-based payment fraud prevention tools were designed for a different era. They use static velocity thresholds that fraudsters reverse-engineer within days. A threshold flagging any debit over $10,000 from a new payee sounds reasonable until a fraud ring splits transactions into $9,800 increments across dozens of accounts.
The deeper problem: traditional systems generate enormous false positive volumes. A compliance team at a mid-sized bank might review 200 to 400 alerts per day with a true-positive rate below 5 percent. That is noise management, not fraud detection.
ACH Fraud Detection Prevention: The Core Challenge
Effective ACH fraud detection prevention requires catching fraud before settlement, ideally before the originating ODFI processes the file. Three constraints define the challenge:
- Speed: ACH same-day files give you hours, not days, to flag and return suspicious entries.
- Context: A debit from a known partner looks identical to a fraudulent one without behavioral context.
- Volume: Enterprise institutions process millions of ACH entries daily. Manual review of more than a small fraction will break under load.
The Cost of Transaction Monitoring at Scale
Transaction monitoring cost is rarely discussed openly. Industry research consistently shows false positives account for up to 85 percent of all alerts reviewed, with each review costing $10 to $50 in analyst time. At 300 alerts per day, that is $1.1 million to $5.5 million annually in manual review cost before penalties or remediation.
The problem compounds when institutions add new rules reactively after each incident. More rules create more alerts, more analyst hours, and diminishing returns on detection quality.
Automated Transaction Monitoring vs. Manual Reviews
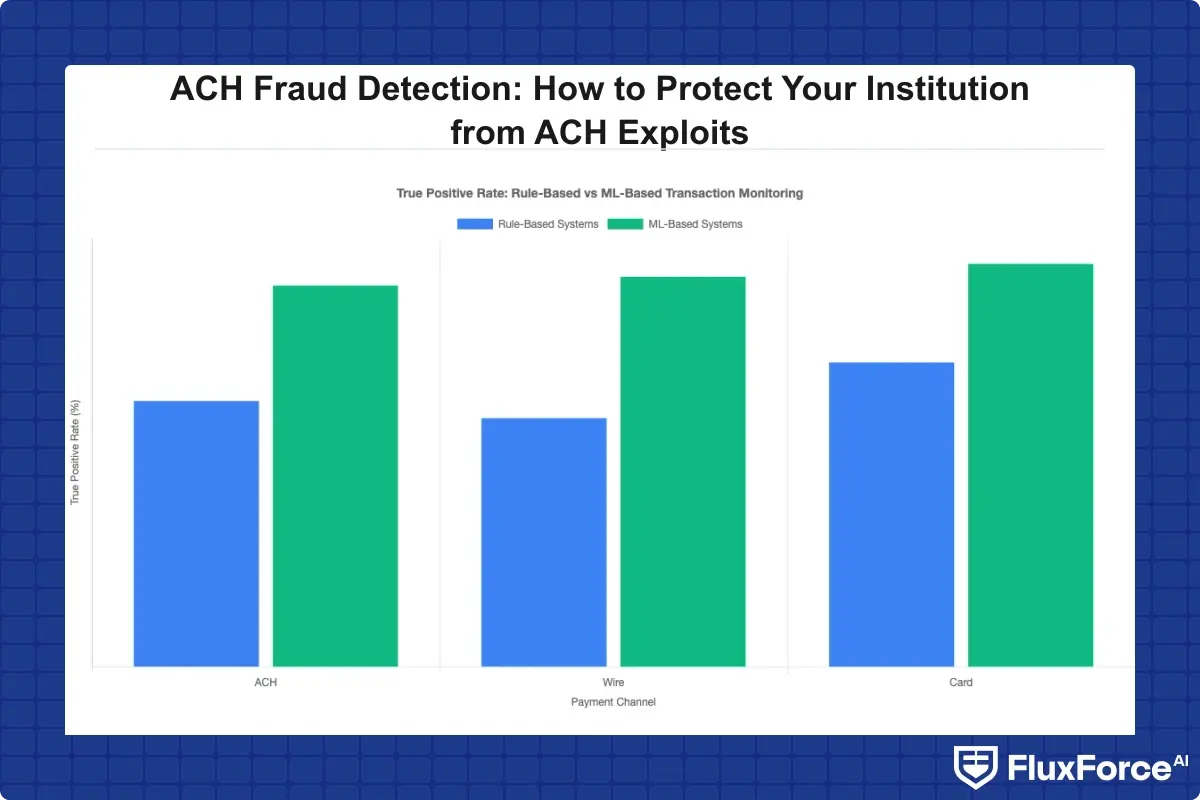
Automated transaction monitoring solves the volume problem but not the precision problem, at least not with rule-based automation. Machine learning changes the equation: a model learns what a normal behavioral baseline looks like for each account and counterparty, then flags deviations rather than threshold breaches.
A rule flags an unusual amount. A model flags that an originator has never sent weekend debits, a counterparty received funds from three synthetic-profile accounts last quarter, and the timing matches patterns from prior confirmed fraud. That is a fundamentally different category of signal.
How AI Fraud Detection Works in Banking
AI fraud detection explained in plain terms: you train a model on millions of labeled transactions so it learns the statistical signatures of fraudulent behavior, then score new transactions in real time against that model. To understand how does AI detect fraud in practice, the answer starts with feature engineering. For ACH, relevant features include originator behavior history, account age, counterparty network relationships, device and IP metadata, and cross-channel signals from card, wire, and login activity.

Machine Learning Fraud Detection: How the Models Learn
Machine learning fraud detection combines several model types in production:
- Supervised classification models (gradient boosting, neural networks): High precision on known fraud patterns, weaker on novel schemes.
- Unsupervised anomaly detection: Identifies statistical outliers from baselines without requiring fraud labels. Better at catching new attack patterns.
- Graph neural networks: Map account, device, and counterparty relationships. Particularly effective for detecting synthetic identity fraud networks sharing device fingerprints.
- Sequence models (LSTM, transformers): Treat transaction history as a time series to catch velocity manipulation and kiting across settlement cycles.
Modern platforms combine these in an ensemble. For a detailed architecture comparison, see our post on AI vs. Traditional Fraud Detection.
Real-Time Fraud Detection Banks Are Deploying Now
Real-time fraud detection for ACH requires scoring at origination, not at batch file review. Real-time fraud detection banks have deployed scoring at the ODFI validation layer, where each ACH entry is scored before transmission to the Federal Reserve or clearing house. Scoring 50,000 entries in under 500 milliseconds requires distributed inference infrastructure and pre-computed feature stores, but institutions that achieve it can reject fraudulent entries before funds leave.
Tackling False Positives in Transaction Monitoring
False positives fraud detection generates more operational cost than the fraud itself at most institutions. Alert quality directly determines how much analyst capacity is available for genuine investigations. Rule-based systems run at 95 to 99 percent false positive rates. Well-tuned ML models typically achieve 60 to 85 percent, a dramatic reduction even if the absolute figure still sounds high.
False Positive Cost Fraud Teams Cannot Ignore
The false positive cost fraud teams should quantify spans direct and indirect components:
- Direct: Analyst hours per alert, case management overhead, escalation workflows.
- Indirect: Customer friction from blocked legitimate transactions, relationship damage on business accounts, lost revenue from held transfers.
At 100,000 daily ACH entries with a 0.1 percent alert rate and a 95 percent false positive rate, you generate 95 wasted reviews per day. At $20 per review, that is $700,000 annually in avoidable overhead before any regulatory cost.
How to Reduce False Positives in AML Programs
How to reduce false positives in AML comes down to model tuning and feedback loops:
- Continuous retraining: Models degrade as fraud patterns shift. Monthly retraining outperforms annual retraining significantly.
- Analyst feedback integration: False positive markings from analysts should update model training data. Most legacy systems skip this step entirely.
- Segment-specific thresholds: A $50,000 transfer is routine for a corporate treasury account and suspicious for a personal account. Uniform thresholds miss this distinction.
- Feature enrichment: Behavioral biometrics, device fingerprints, and network graph data give models more signal to separate fraud from benign anomalies.
To reduce false positives transaction monitoring teams can also use risk-based escalation, auto-closing low-risk cases and routing only medium and high-risk alerts to analysts.
Fraud Alert Fatigue: When Analysts Stop Trusting the System
Fraud alert fatigue is a documented operational hazard. Analysts reviewing hundreds of low-quality alerts daily develop pattern blindness, approve alerts faster, rely on surface cues, and miss genuine fraud buried in the noise. High alert volume paradoxically reduces detection effectiveness. Our analysis of how agentic AI cuts false positives by 80% shows how closed-loop feedback systems solve this at scale.
Synthetic Identity Fraud and ACH: A Growing Threat
Synthetic identity fraud is the fastest-growing financial crime in the U.S., according to the Federal Reserve's payments fraud research. A synthetic identity combines real PII, often a stolen Social Security number, with fabricated details to create a profile with no real victim to report it.
These identities spend 6 to 18 months building credit history and ACH relationships before executing bust-out fraud, maximizing all available credit and pull capacity before abandoning the identity.
How Synthetic Identities Slip Through ACH Controls
Traditional ACH fraud detection prevention systems check account age, credit scores, and KYC data. A well-built synthetic identity passes all three. What it cannot fake is behavioral consistency across accounts, device fingerprints, and network relationships. Graph-based detection identifies synthetic clusters through shared infrastructure: same device across multiple accounts, matching IP ranges, common beneficiary accounts, and similar transaction timing. This is why detecting synthetic identity fraud in real time requires a graph approach, not account-level scoring alone.

Choosing the Right Fraud Detection Software for Your Institution
ACH fraud detection software selection affects compliance, operations, and technology teams simultaneously. Meaningful variation remains in how platforms handle scoring latency, false positive controls, and return code feedback.
Sardine vs Unit21: What Compliance Teams Should Know
The sardine vs unit21 comparison comes up frequently in compliance technology evaluations. Sardine is purpose-built for real-time transaction risk scoring with deep fintech integrations, making it stronger for origination-layer ACH scoring. Unit21 focuses on case management and SAR filing workflows with a rule-authoring interface non-technical teams can operate independently.
For ACH-specific fraud detection, the key questions are: Does the platform score at origination or settlement? Does it support behavioral biometrics natively? How does it handle return code feedback? For institutions considering ACH fraud detection prevention software that spans ACH, card, and wire channels, evaluating against your batch processing architecture before committing is essential.
AI Fraud Detection Software Evaluation Checklist
When evaluating ai fraud detection software for ACH workflows, assess:
- Scoring latency: Can it score ACH entries under 500ms at origination?
- Feature support: Does it ingest device fingerprints and network graph data beyond transaction features?
- False positive controls: Does it support segment-specific thresholds and analyst feedback loops?
- Regulatory alignment: Is SAR and CTR filing integrated or does it require a separate platform?
- Return code learning: Does the system update scoring from R02 and R08 return codes?
- Explainability: Can it justify each flag for analysts and examiners?
Total transaction monitoring cost for a dedicated platform typically runs $150,000 to $600,000 annually at mid-market scale. The card fraud analytics post covers multi-channel evaluation criteria in more depth.
Onboard Customers in Seconds
Conclusion
ACH fraud detection prevention is not a problem you solve once. It requires continuous model improvement, analyst feedback integration, and architectural investment in scoring at origination rather than at settlement. Institutions that outperform on ACH fraud metrics score in real time before batch transmission, manage fraud alert fatigue through false positive reduction, and treat synthetic identity fraud as a graph problem rather than an account-level one.
If your transaction monitoring software is generating hundreds of low-quality daily alerts, the issue is architectural. The move to machine learning fraud detection pays back in analyst capacity, detection quality, and reduced transaction monitoring cost within the first year. Start by auditing your false positive rate fraud detection metrics and mapping them against your alert review capacity. That gap is where your next investment should go.



Share this article